
Apache演练读取gz和snappy性能
Apache演练读取gz和snappy性能
提问于 2016-09-07 11:37:07
我用的是Apache钻头1.8。为了测试海豚,我用.csv制作了两个拼花文件。CSV的大小约为4GB,gz编解码器为120 4GB,第二部分为250 4GB左右。
由于Spark使用snappy作为默认编解码器,而且snappy在性能上应该更快,我面临一个问题。
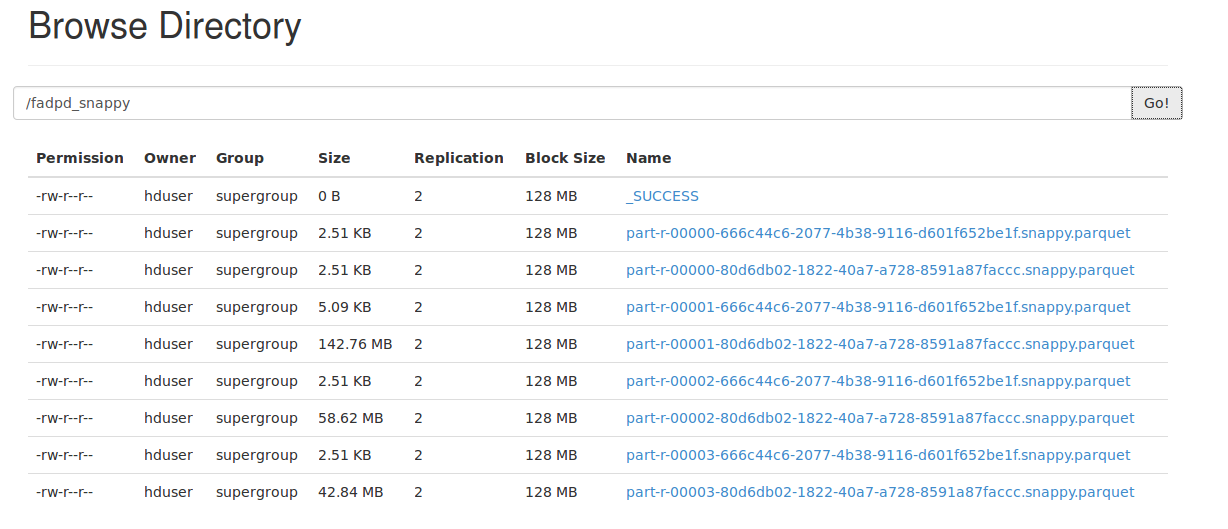
这是我在Hadoop上具有块大小等的文件:
- 使用snappy编解码器:
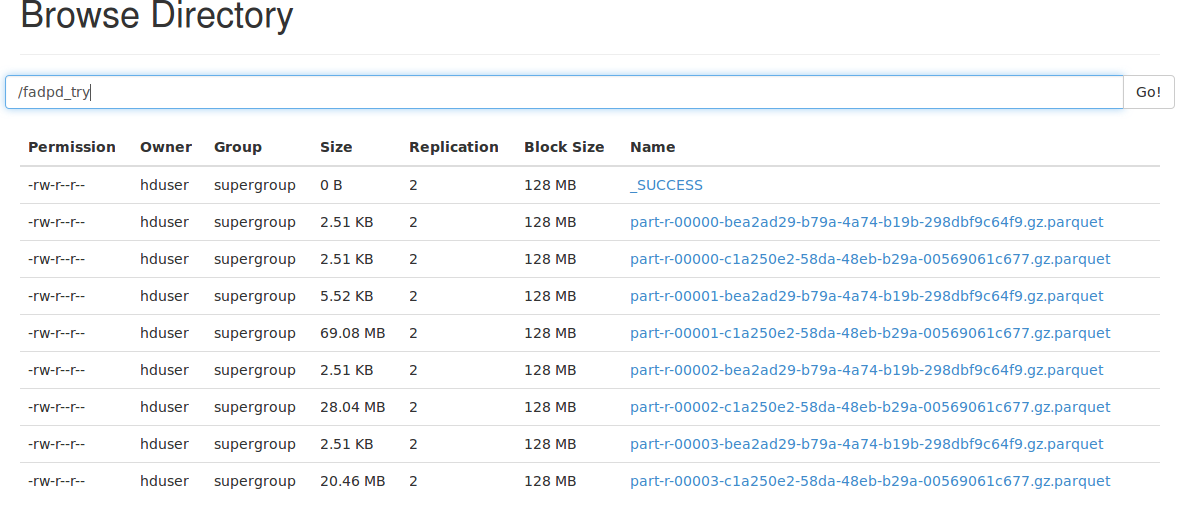
- 使用gz编解码器:
当我试图在Drill (默认情况下有snappy编解码器)查询的时候,snappy编解码器上的拼花文件大约是18秒。使用相同的查询在gz编解码器上的钻片文件中查询的时间大约是8秒。
(这是带有select 5列的简单查询,按一个列排序,对一个列进行限制)
我现在有点糊涂了。使用I/O不是更有效吗?我是在哪里搞错了,还是这样做的。如果有人能解释这一点,我会非常感激的,因为我在网上找不到有用的东西。再一次谢谢你!
回答 1
Stack Overflow用户
发布于 2020-01-02 21:00:12
在您最初的帖子中,您说带有snappy文件的拼花是250 GB,是指250 MB吗?
至少对于HDFS,您希望拼花文件大小(行组)与块大小相等。您可能会遇到问题,因为您的块大小为128 MB,文件大小为250 MB。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/39368864
复制相关文章
相似问题
腾讯云开发者
