
在C#中从PDF中提取格式信息
我需要制定一个程序,可以分析和理解在某些PDF中的特定结构和格式的内容的上下文和语义关系。
下面是一个示例,其中显示了这种PDF的一段内容:
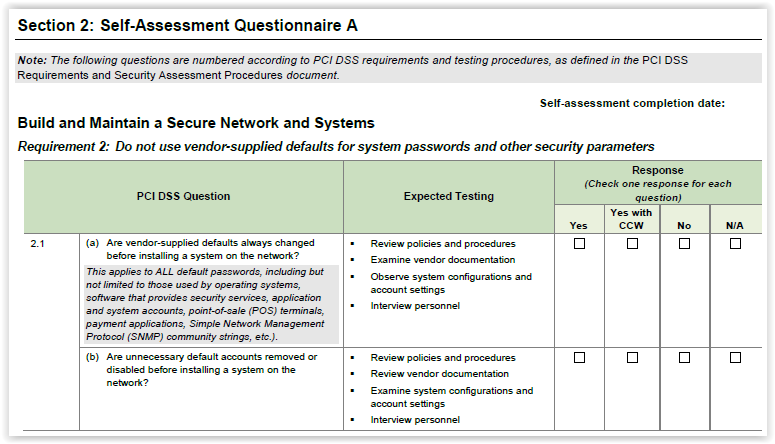
因此,我需要一个PDF阅读库,它不仅可以提取文本,还可以提取PDF中的流星数据,如字体大小、字体样式(粗体、塔利)、背景色、表及其子元素、表格单元格背景颜色、复选框、元素位置等。
是否有任何免费的.NET库可以完成这项工作?非常感谢。
PS:我知道这篇文章:Extract Data from .PDF files,但是图书馆的局限性没有被详细阐述。
回答 2
Stack Overflow用户
发布于 2016-11-25 05:03:54
我没有一个快速的答案,但在过去的两周里,我成功地解决了这个问题。我使用Apache PDFBox,它将PDF文本提取到TextPositions中。这些TextPositions包含关于文本中每个字符的信息(位置、粗体、斜体、字体等)。我使用这些信息为所有表元素设置边界框,并决定文本对齐、列成员身份等内容,然后在Excel中重新创建PDF页面及其表格,代码行数略低于1000行。
我不需要提取像复选框这样的图形元素,但是Apache PDFBox确实可以提取到COSStreams,图形和表单元素很可能可以从这些流中被解析--我还没有。我的代码将能够重建您显示的表,并且只会丢失复选框和背景色。
我一直在寻找一个比我的更简单的解决方案,但结果却很短,似乎没有简单的方法可以做到这一点。
编辑:如果这没有劝阻你,我可以教你如何开始。首先,扩展PDFTextStripper或PDFTextStripperByArea。这使您可以通过TextPositions覆盖访问processTextPosition --下面的代码演示了如何将TextPositions转换为自己的自定义类TextChar。然后,我使用相关的文本位置来计算基本的上下文信息:
public class PDFStripper : PDFTextStripper
{
private List<TextChar>[] tcPages;
public PDFStripper(java.util.List pages)
{
int pagecount = pages.size();
tcPages = new List<TextChar>[pagecount+1];
base.processPages(pages);
}
protected override void processTextPosition(TextPosition tp)
{
PDGraphicsState gs = getGraphicsState();
TextChar tc = BuildTextChar(tp, gs);
int currentPageNo = getCurrentPageNo();
if (tcPages.ElementAtOrDefault(currentPageNo) == null)
{
tcPages[currentPageNo] = new List<TextChar>();
}
tcPages[currentPageNo].Add(tc);
}
private static TextChar BuildTextChar(TextPosition tp, PDGraphicsState gstate)
{
TextChar tc = new TextChar();
tc.Char = tp.getCharacter()[0];
float h = (float)Math.Floor(tp.getHeightDir());
tc.Box = new RectangleF
(
tp.getXDirAdj(),
(float)Math.Round(tp.getYDirAdj(), 0, MidpointRounding.ToEven) - h, // adjusted Y to top
tp.getWidthDirAdj(),
h
);
tc.Direction = tp.getDir();
tc.SpaceWidth = tp.getWidthOfSpace();
tc.Font = tp.getFont().getBaseFont();
tc.FontSize = tp.getFontSizeInPt();
try
{
int[] flags =
GetBits(tp.getFont().getFontDescriptor().getFlags());
tc.IsBold = findBold(tp, flags, gstate);
tc.IsItalic = findItalics(tp, flags);
}
catch { }
return tc;
}
protected override void writePage() { return; } //prevents exception
}Stack Overflow用户
发布于 2016-11-18 01:12:50
添加此NuGet包https://www.nuget.org/packages/TikaOnDotNet/。这是apache的dotnet版本
然后这样做:
var extracted = new TikaOnDotNet.TextExtractor().Extract("file.pdf");
var text = extracted.Text;
var metaData = extracted.Metadata;祝你好运兄弟:)
https://stackoverflow.com/questions/40667520
复制相似问题
腾讯云开发者
