
如何在大熊猫中以这种方式转换栏
如何在大熊猫中以这种方式转换栏
提问于 2016-12-07 14:46:46
原始数据如下:
df=pd.DataFrame({'A': [1]*3 + [2]*3 + [1]*4 + [3]*5,
'B': [1.5]*2 + [2]*4 + [1.5]*5 + [3.2]*4})如何将列A和B转换为:
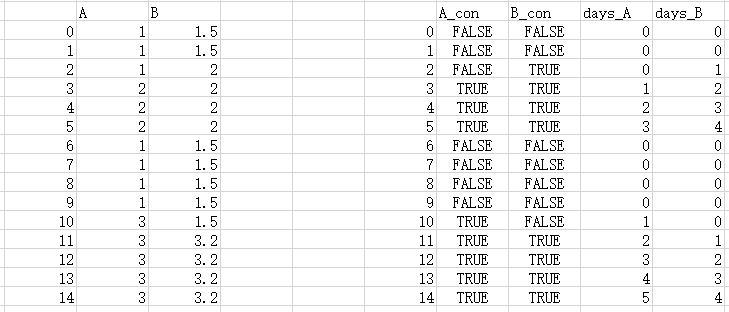
A_con和B_con的规则是:
A_con=0;if(Ai>Ai-1,A_coni=True,if(Ai=Ai-1& A_coni-1==True,A_coni=True,A_coni=False)
days_A和days_B的规则是:
如果(A_coni==True,days_Ai=days_Ai-1+1,days_Ai=0)
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-12-07 16:04:44
diff方法接受当前行和它上面的行之间的差异。任何积极的事情都会使A_con成为现实。棘手的部分是当差值为0时。当0时,上面的直接值可以代替它的位置。这是使用replace和ffill方法完成的。负责A_con和B_con
对于days列,我们采用一种方法,首先对A_con列的整个列(True值计算为1)使用df['A_con'].cumsum()进行累加和。这显然超过了计数,因为我们必须将A_con中的任何假值重置为0,并在True时再次开始计数。
要做到这一点,当A_con为False时,将减去整个累积和。但是,当A_con为真时,只需要减去直到最后一个假的累加,这样计数才能继续。这再次通过替换所有True值(现在用1 - a_cum.diff()计算为0)来完成,方法是在A_con为False时,用最后一次累积和进行前向填充。
# create a little more data to test
df=pd.DataFrame({'A': [1]*3 + [2]*3 + [1]*4 + [3]*5 + [2.2]*3 + [2.4]*3,
'B': [1.5]*2 + [2]*4 + [1.5]*5 + [3.2]*4 + [2.2]*3 + [2.4]*3})
df['A_con'] = df['A'].diff().replace(0, method='ffill') > 0
a_cum = df['A_con'].cumsum()
a_cum_sub = (a_cum * (1 - a_cum.diff())).replace(0, method='ffill').fillna(0)
df['days_A'] = a_cum - a_cum_sub
df['B_con'] = df['B'].diff().replace(0, method='ffill') > 0
b_cum = df['B_con'].cumsum()
b_cum_sub = (b_cum * (1 - b_cum.diff())).replace(0, method='ffill').fillna(0)
df['days_B'] = b_cum - b_cum_sub带输出
A B A_con days_A B_con days_B
0 1.0 1.5 False 0.0 False 0.0
1 1.0 1.5 False 0.0 False 0.0
2 1.0 2.0 False 0.0 True 1.0
3 2.0 2.0 True 1.0 True 2.0
4 2.0 2.0 True 2.0 True 3.0
5 2.0 2.0 True 3.0 True 4.0
6 1.0 1.5 False 0.0 False 0.0
7 1.0 1.5 False 0.0 False 0.0
8 1.0 1.5 False 0.0 False 0.0
9 1.0 1.5 False 0.0 False 0.0
10 3.0 1.5 True 1.0 False 0.0
11 3.0 3.2 True 2.0 True 1.0
12 3.0 3.2 True 3.0 True 2.0
13 3.0 3.2 True 4.0 True 3.0
14 3.0 3.2 True 5.0 True 4.0
15 2.2 2.2 False 0.0 False 0.0
16 2.2 2.2 False 0.0 False 0.0
17 2.2 2.2 False 0.0 False 0.0
18 2.4 2.4 True 1.0 True 1.0
19 2.4 2.4 True 2.0 True 2.0
20 2.4 2.4 True 3.0 True 3.0页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/41020437
复制相关文章
相似问题
腾讯云开发者
