如何通过动态资源分配运行spark + cassandra + mesos (dcos)?
如何通过动态资源分配运行spark + cassandra + mesos (dcos)?
提问于 2016-12-09 07:11:11
在通过马拉松的每个从节点上,我们运行Mesos外部Shu浮服务。当我们在粗粒度模式下通过dcos CLI提交spark作业时,没有动态分配,一切都按预期工作。但是,当我们提交相同的任务时,动态分配会失败。
16/12/08 19:20:42 ERROR OneForOneBlockFetcher: Failed while starting block fetches
java.lang.RuntimeException: java.lang.RuntimeException: Failed to open file:/tmp/blockmgr-d4df5df4-24c9-41a3-9f26-4c1aba096814/30/shuffle_0_0_0.index
at org.apache.spark.network.shuffle.ExternalShuffleBlockResolver.getSortBasedShuffleBlockData(ExternalShuffleBlockResolver.java:234)
...
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:354)
...
Caused by: java.io.FileNotFoundException: /tmp/blockmgr-d4df5df4-24c9-41a3-9f26-4c1aba096814/30/shuffle_0_0_0.index (No such file or directory)详细说明:
- 我们使用Azure安装了带有马拉松的Mesos (DCOS)。
- 通过我们安装的宇宙软件包:卡桑德拉,火花和马拉松-lb。
- 我们在卡桑德拉生成了测试数据。
- 我在笔记本电脑上安装了dcos CLI
当我按下面的方式提交工作时,一切都如预期的那样工作:
./dcos spark run --submit-args="--properties-file coarse-grained.conf --class portal.spark.cassandra.app.ProductModelPerNrOfAlerts http://marathon-lb-default.marathon.mesos:10018/jars/spark-cassandra-assembly-1.0.jar"
Run job succeeded. Submission id: driver-20161208185927-0043
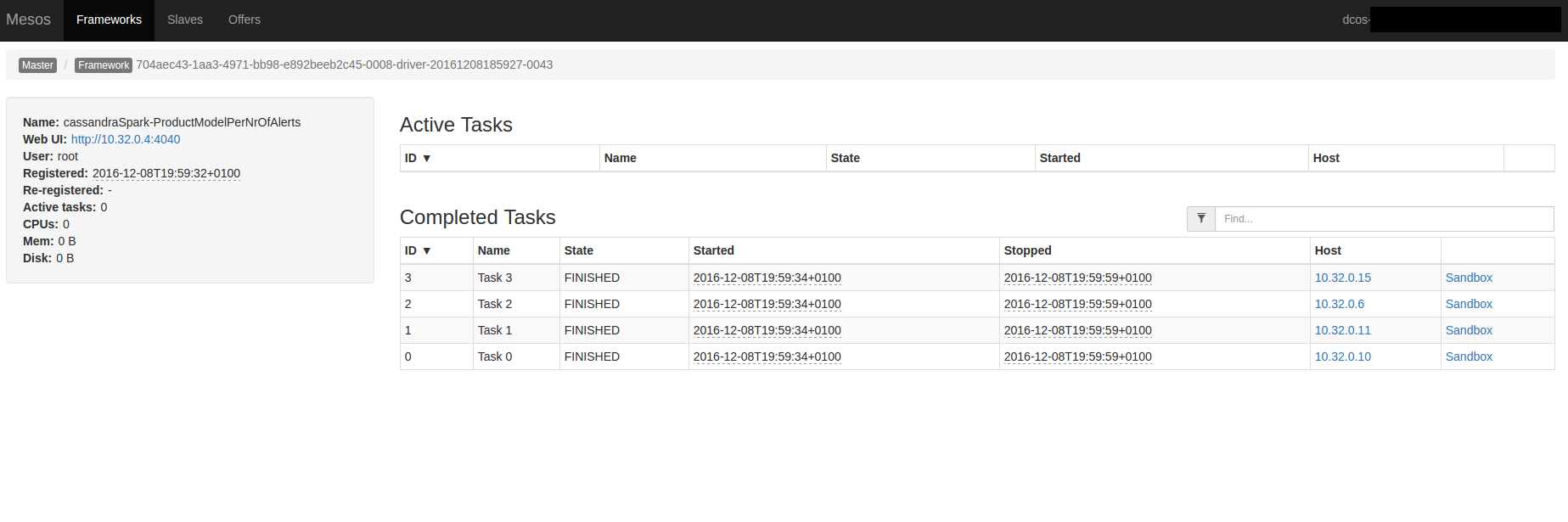
cqlsh:sp> select count(*) from product_model_per_alerts_by_date ;
count
-------
476coarse-grained.conf:
spark.cassandra.connection.host 10.32.0.17
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.executor.cores 1
spark.executor.memory 1g
spark.executor.instances 2
spark.submit.deployMode cluster
spark.cores.max 4portal.spark.cassandra.app.ProductModelPerNrOfAlerts:
package portal.spark.cassandra.app
import org.apache.spark.sql.{SQLContext, SaveMode}
import org.apache.spark.{SparkConf, SparkContext}
object ProductModelPerNrOfAlerts {
def main(args: Array[String]): Unit = {
val conf = new SparkConf(true)
.setAppName("cassandraSpark-ProductModelPerNrOfAlerts")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
val df = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(Map("table" -> "asset_history", "keyspace" -> "sp"))
.load()
.select("datestamp","product_model","nr_of_alerts")
val dr = df
.groupBy("datestamp","product_model")
.avg("nr_of_alerts")
.toDF("datestamp","product_model","nr_of_alerts")
dr.write
.mode(SaveMode.Overwrite)
.format("org.apache.spark.sql.cassandra")
.options(Map("table" -> "product_model_per_alerts_by_date", "keyspace" -> "sp"))
.save()
sc.stop()
}
}动态分配
通过马拉松,我们运行Mesos外部洗牌服务:
{
"id": "spark-mesos-external-shuffle-service-tt",
"container": {
"type": "DOCKER",
"docker": {
"image": "jpavt/mesos-spark-hadoop:mesos-external-shuffle-service-1.0.4-2.0.1",
"network": "BRIDGE",
"portMappings": [
{ "hostPort": 7337, "containerPort": 7337, "servicePort": 7337 }
],
"forcePullImage":true,
"volumes": [
{
"containerPath": "/tmp",
"hostPath": "/tmp",
"mode": "RW"
}
]
}
},
"instances": 9,
"cpus": 0.2,
"mem": 512,
"constraints": [["hostname", "UNIQUE"]]
}用于jpavt/mesos-spark-hadoop:mesos-external-shuffle-service-1.0.4-2.0.1:的文档
FROM mesosphere/spark:1.0.4-2.0.1
WORKDIR /opt/spark/dist
ENTRYPOINT ["./bin/spark-class", "org.apache.spark.deploy.mesos.MesosExternalShuffleService"]现在,当我提交带有动态分配的作业时,它会失败:
./dcos spark run --submit-args="--properties-file dynamic-allocation.conf --class portal.spark.cassandra.app.ProductModelPerNrOfAlerts http://marathon-lb-default.marathon.mesos:10018/jars/spark-cassandra-assembly-1.0.jar"
Run job succeeded. Submission id: driver-20161208191958-0047
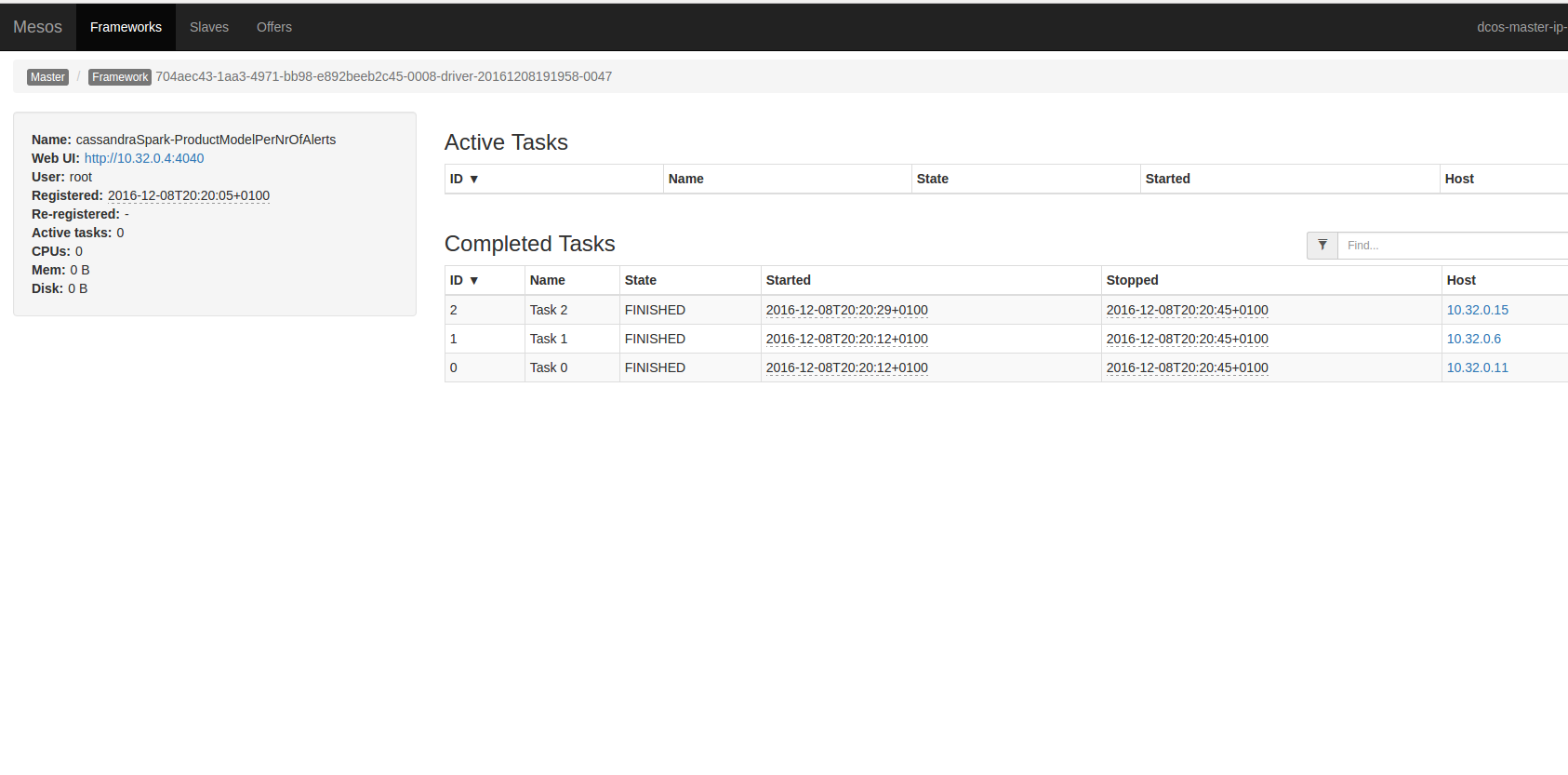
select count(*) from product_model_per_alerts_by_date ;
count
-------
5dynamic-allocation.conf
spark.cassandra.connection.host 10.32.0.17
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.executor.cores 1
spark.executor.memory 1g
spark.submit.deployMode cluster
spark.cores.max 4
spark.shuffle.service.enabled true
spark.dynamicAllocation.enabled true
spark.dynamicAllocation.minExecutors 2
spark.dynamicAllocation.maxExecutors 5
spark.dynamicAllocation.cachedExecutorIdleTimeout 120s
spark.dynamicAllocation.schedulerBacklogTimeout 10s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 20s
spark.mesos.executor.docker.volumes /tmp:/tmp:rw
spark.local.dir /tmp来自mesos的日志:
16/12/08 19:20:42 INFO MemoryStore: Block broadcast_7_piece0 stored as bytes in memory (estimated size 18.0 KB, free 366.0 MB)
16/12/08 19:20:42 INFO TorrentBroadcast: Reading broadcast variable 7 took 21 ms
16/12/08 19:20:42 INFO MemoryStore: Block broadcast_7 stored as values in memory (estimated size 38.6 KB, free 366.0 MB)
16/12/08 19:20:42 INFO MapOutputTrackerWorker: Don't have map outputs for shuffle 0, fetching them
16/12/08 19:20:42 INFO MapOutputTrackerWorker: Doing the fetch; tracker endpoint = NettyRpcEndpointRef(spark://MapOutputTracker@10.32.0.4:45422)
16/12/08 19:20:42 INFO MapOutputTrackerWorker: Got the output locations
16/12/08 19:20:42 INFO ShuffleBlockFetcherIterator: Getting 4 non-empty blocks out of 58 blocks
16/12/08 19:20:42 INFO TransportClientFactory: Successfully created connection to /10.32.0.11:7337 after 2 ms (0 ms spent in bootstraps)
16/12/08 19:20:42 INFO ShuffleBlockFetcherIterator: Started 1 remote fetches in 13 ms
16/12/08 19:20:42 ERROR OneForOneBlockFetcher: Failed while starting block fetches java.lang.RuntimeException: java.lang.RuntimeException: Failed to open file: /tmp/blockmgr-d4df5df4-24c9-41a3-9f26-4c1aba096814/30/shuffle_0_0_0.index
at org.apache.spark.network.shuffle.ExternalShuffleBlockResolver.getSortBasedShuffleBlockData(ExternalShuffleBlockResolver.java:234)
...
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:354)
...
Caused by: java.io.FileNotFoundException: /tmp/blockmgr-d4df5df4-24c9-41a3-9f26-4c1aba096814/30/shuffle_0_0_0.index (No such file or directory)来自马拉松spark-mesos-external-shuffle-service-tt:的日志
...
16/12/08 19:20:29 INFO MesosExternalShuffleBlockHandler: Received registration request from app 704aec43-1aa3-4971-bb98-e892beeb2c45-0008-driver-20161208191958-0047 (remote address /10.32.0.4:49710, heartbeat timeout 120000 ms).
16/12/08 19:20:31 INFO ExternalShuffleBlockResolver: Registered executor AppExecId{appId=704aec43-1aa3-4971-bb98-e892beeb2c45-0008-driver-20161208191958-0047, execId=2} with ExecutorShuffleInfo{localDirs=[/tmp/blockmgr-14525ef0-22e9-49fb-8e81-dc84e5fba8b2], subDirsPerLocalDir=64, shuffleManager=org.apache.spark.shuffle.sort.SortShuffleManager}
16/12/08 19:20:38 ERROR TransportRequestHandler: Error while invoking RpcHandler#receive() on RPC id 8157825166903585542
java.lang.RuntimeException: Failed to open file: /tmp/blockmgr-14525ef0-22e9-49fb-8e81-dc84e5fba8b2/16/shuffle_0_55_0.index
at org.apache.spark.network.shuffle.ExternalShuffleBlockResolver.getSortBasedShuffleBlockData(ExternalShuffleBlockResolver.java:234)
...
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:354)
Caused by: java.io.FileNotFoundException: /tmp/blockmgr-14525ef0-22e9-49fb-8e81-dc84e5fba8b2/16/shuffle_0_55_0.index (No such file or directory)
...但是文件存在于给定的从框上:
$ ls -l /tmp/blockmgr-14525ef0-22e9-49fb-8e81-dc84e5fba8b2/16/shuffle_0_55_0.index
-rw-r--r-- 1 root root 1608 Dec 8 19:20 /tmp/blockmgr-14525ef0-22e9-49fb-8e81-dc84e5fba8b2/16/shuffle_0_55_0.index
stat shuffle_0_55_0.index
File: 'shuffle_0_55_0.index'
Size: 1608 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 1805493 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2016-12-08 19:20:38.163188836 +0000
Modify: 2016-12-08 19:20:38.163188836 +0000
Change: 2016-12-08 19:20:38.163188836 +0000
Birth: -回答 2
Stack Overflow用户
回答已采纳
发布于 2016-12-12 14:06:44
在马拉松式外部洗牌服务配置中出现错误,而不是路径container.docker.volumes,我们应该使用container.volumes路径。
正确配置:
{
"id": "mesos-external-shuffle-service-simple",
"container": {
"type": "DOCKER",
"docker": {
"image": "jpavt/mesos-spark-hadoop:mesos-external-shuffle-service-1.0.4-2.0.1",
"network": "BRIDGE",
"portMappings": [
{ "hostPort": 7337, "containerPort": 7337, "servicePort": 7337 }
],
"forcePullImage":true
},
"volumes": [
{
"containerPath": "/tmp",
"hostPath": "/tmp",
"mode": "RW"
}
]
},
"instances": 9,
"cpus": 0.2,
"mem": 512,
"constraints": [["hostname", "UNIQUE"]]
}Stack Overflow用户
发布于 2016-12-10 03:47:40
我不熟悉DCOS,马拉松和Azure,我使用动态资源分配( Mesos外部洗牌服务)在Mesos和Aurora与Docker。
- 每个Mesos代理节点都有自己的外部洗牌服务(即一个mesos代理的一个外部洗牌服务)?
spark.local.dir设置是完全相同的字符串和指向相同的目录?不过,您的洗牌spark.local.dir服务是/tmp,我不知道DCOS设置。spark.local.dir目录对两者都可以读/写吗?如果码头启动了mesos代理和外部洗牌服务,则必须将主机上的spark.local.dir安装到两个容器上。
编辑
- 如果设置了SPARK_LOCAL_DIRS (mesos或独立的)环境变量,
spark.local.dir将被重写。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/41054952
复制相关文章
相似问题
腾讯云开发者
