
如何为cudaMemAdviseSetPreferredLocation指定GPU id
如何为cudaMemAdviseSetPreferredLocation指定GPU id
提问于 2016-12-09 10:52:45
在尝试将托管内存的首选位置设置为GPU #0时,我一直得到“无效设备序号”:
CUDA_ERR_CHECK(cudaMemAdvise(deviceMemoryHeap.pool, size,
cudaMemAdviseSetPreferredLocation, 0));唯一起作用的是cudaCpuDeviceId。那么,如何指定GPU id呢?
编辑添加了一个简单的示例:
#define CUDA_ERR_CHECK(x) \
do { cudaError_t err = x; if (err != cudaSuccess) { \
fprintf(stderr, "CUDA error %d \"%s\" at %s:%d\n", \
(int)err, cudaGetErrorString(err), \
__FILE__, __LINE__); \
exit(1); \
}} while (0);
#include <cstdio>
template<typename T>
__global__ void kernel(size_t* value)
{
*value = sizeof(T);
}
int main()
{
size_t size = 1024 * 1024 * 1024;
size_t* managed = NULL;
CUDA_ERR_CHECK(cudaMallocManaged(&managed, size, cudaMemAttachGlobal));
CUDA_ERR_CHECK(cudaMemAdvise(managed, size,
cudaMemAdviseSetPreferredLocation, 0));
kernel<double><<<1, 1>>>(managed);
CUDA_ERR_CHECK(cudaGetLastError());
CUDA_ERR_CHECK(cudaDeviceSynchronize());
CUDA_ERR_CHECK(cudaFree(managed));
size_t* memory = NULL;
CUDA_ERR_CHECK(cudaMalloc(&memory, size));
kernel<double><<<1, 1>>>(memory);
CUDA_ERR_CHECK(cudaGetLastError());
CUDA_ERR_CHECK(cudaDeviceSynchronize());
CUDA_ERR_CHECK(cudaFree(memory));
return 0;
}抛出错误:
$ make
nvcc -arch=sm_30 managed.cu -o managed
$ ./managed
CUDA error 10 "invalid device ordinal" at managed.cu:24库达8.0
我的目标是消除巨大的cudaLaunch调用延迟,只有在托管内存内核启动时才会发生这种情况:
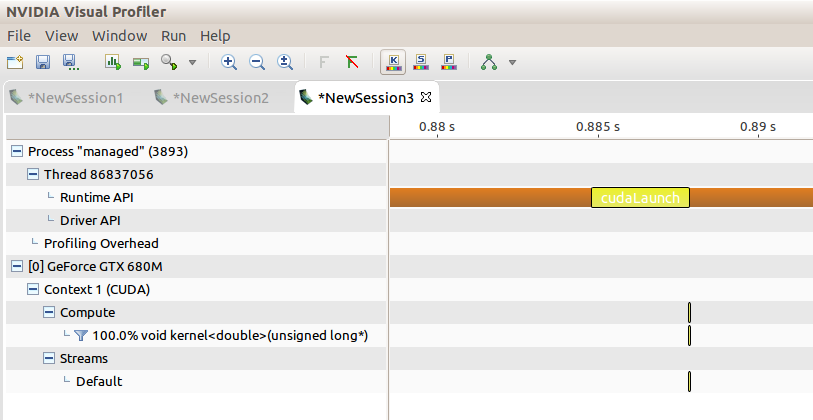
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-12-10 02:52:59
此错误似乎源于缺少设备功能。正如cudaMemAdvise函数的CUDA文档所述:
如果设备是GPU,那么它必须具有设备属性
cudaDevAttrConcurrentManagedAccess的非零值。
您应该调用以下代码以确保设备可用于并发托管使用:
int device_id = 0, result = 0;
cudaDeviceGetAttribute (&result, cudaDevAttrConcurrentManagedAccess, device_id);
if (result) {
// Call cudaMemAdvise
}页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/41058748
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号