
熊猫在多个条件下计算多列和
熊猫在多个条件下计算多列和
提问于 2016-12-20 01:15:36
我有一张宽桌,格式如下(最多可容纳10人):
person1_status | person2_status | person3_status | person1_type | person_2 type | person3_type
0 | 1 | 0 | 7 | 4 | 6 其中状态可以是0或1(前3科尔)。
其中类型的可以是从4-7范围内的#。这里的值对应于另一个表,该表根据类型指定值。所以..。
Type | Value
4 | 10
5 | 20
6 | 30
7 | 40我需要计算'A‘和'B’两列,其中:
- A是每个人的类型(在该行中)的值的和,其中status = 0。
- B是每个人的值(在该行中)的值的和,其中status = 1。
例如,生成的列'A‘和'B’如下:
A | B
70 | 10对此的解释:
‘’具有值70,因为person1和person3具有“状态”0,并且相应的类型为7和6(对应于值30和40)。
类似地,应该有另一个列'B‘,它的值为"10“,因为只有person2具有状态"1”,并且它们的类型是"4“(对应值为10)。
这也许是个愚蠢的问题,但我该如何用矢量化的方式来做到这一点呢?我不想使用for循环什么的,因为它的效率会降低.
我希望这有道理..。有人能帮我吗?我想我已经脑死亡了想办法解决这个问题。
对于比较简单的计算列,我只使用了np.where,但是我有点被困在这里了,因为我需要计算多个列的值之和,给定一定的条件,同时从一个单独的表中提取这些值。
有意义的希望
回答 2
Stack Overflow用户
回答已采纳
发布于 2016-12-20 01:37:31
使用filter方法,该方法将筛选出现字符串的列名。
为查找值other_table创建一个数据帧,并将索引设置为类型列。
df_status = df.filter(like = 'status')
df_type = df.filter(like = 'type')
df_type_lookup = df_type.applymap(lambda x: other_table.loc[x]).values
df['A'] = np.sum((df_status == 0).values * df_type_lookup, 1)
df['B'] = np.sum((df_status == 1).values * df_type_lookup, 1)以下是完整的例子:
创建假数据
df = pd.DataFrame({'person_1_status':np.random.randint(0, 2,1000) ,
'person_2_status':np.random.randint(0, 2,1000),
'person_3_status':np.random.randint(0, 2,1000),
'person_1_type':np.random.randint(4, 8,1000),
'person_2_type':np.random.randint(4, 8,1000),
'person_3_type':np.random.randint(4, 8,1000)},
columns= ['person_1_status', 'person_2_status', 'person_3_status',
'person_1_type', 'person_2_type', 'person_3_type'])
person_1_status person_2_status person_3_status person_1_type \
0 1 0 0 7
1 0 1 0 6
2 1 0 1 7
3 0 0 0 7
4 0 0 1 4
person_3_type person_3_type
0 5 5
1 7 7
2 7 7
3 7 7
4 7 7 制作other_table
other_table = pd.Series({4:10, 5:20, 6:30, 7:40})
4 10
5 20
6 30
7 40
dtype: int64将状态和类型列筛选出到它们自己的数据格式。
df_status = df.filter(like = 'status')
df_type = df.filter(like = 'type')组合查找表
df_type_lookup = df_type.applymap(lambda x: other_table.loc[x]).values在行之间应用矩阵乘法和和。
df['A'] = np.sum((df_status == 0).values * df_type_lookup, 1)
df['B'] = np.sum((df_status == 1).values * df_type_lookup, 1)输出
person_1_status person_2_status person_3_status person_1_type \
0 0 0 1 7
1 0 1 0 4
2 0 1 1 7
3 0 1 0 6
4 0 0 1 5
person_2_type person_3_type A B
0 7 5 80 20
1 6 4 20 30
2 5 5 40 40
3 6 4 40 30
4 7 5 60 20 Stack Overflow用户
发布于 2016-12-20 01:51:29
考虑一下dataframe df
mux = pd.MultiIndex.from_product([['status', 'type'], ['p%i' % i for i in range(1, 6)]])
data = np.concatenate([np.random.choice((0, 1), (10, 5)), np.random.rand(10, 5)], axis=1)
df = pd.DataFrame(data, columns=mux)
df
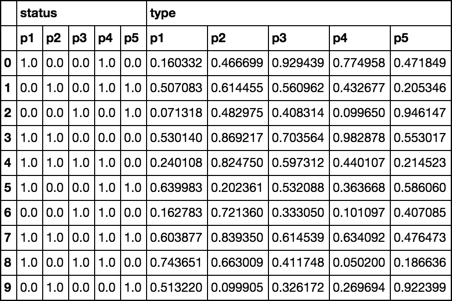
这个结构的方式我们可以为type == 1这样做
df.status.mul(df.type).sum(1)
0 0.935290
1 1.252478
2 1.354461
3 1.399357
4 2.102277
5 1.589710
6 0.434147
7 2.553792
8 1.205599
9 1.022305
dtype: float64对于type == 0
df.status.rsub(1).mul(df.type).sum(1)
0 1.867986
1 1.068045
2 0.653943
3 2.239459
4 0.214523
5 0.734449
6 1.291228
7 0.614539
8 0.849644
9 1.109086
dtype: float64可以使用以下代码以这种格式获取列
df.columns = df.columns.str.split('_', expand=True)
df = df.swaplevel(0, 1, 1)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/41233496
复制相关文章
相似问题
腾讯云开发者
