
ggplot + scale_size_area,如何显示来自另一个cat变量的比例
ggplot + scale_size_area,如何显示来自另一个cat变量的比例
提问于 2016-12-20 12:05:05
在成功地绘制了分类和分类数据之后
ggplot(data=data_big, aes(job, education)) +
geom_count() +
scale_size_area(max_size = 12)+
theme_bw()+
theme(axis.text.x=element_text(angle=45,hjust=1))
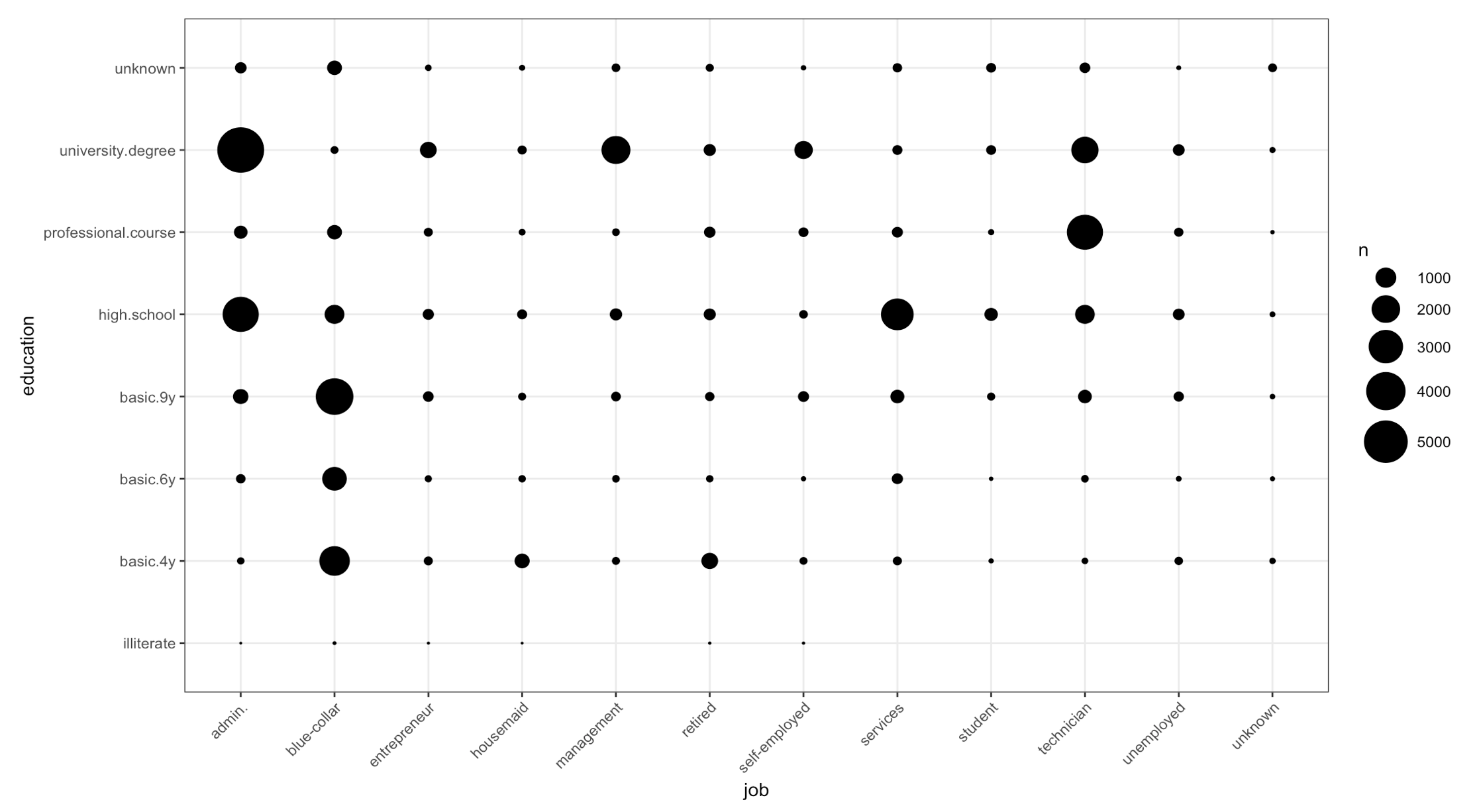
我想添加一个维度,使这些点成为“迷你饼图”。基本上,我想添加关于另一个(二进制)分类数据的信息。
我计算了那些比例
data_big %>% group_by(job,education,y) %>% summarise(n=n()) %>% mutate(rel.freq = round(100 * n/sum(n), 2)))给出一个类似于(不完整的tbl)的表
职业教育y/n q rel.freq
admin. illiterate no 1 100.00
admin. basic.4y yes 10 12.99
admin. basic.4y no 67 87.01
admin. basic.6y yes 8 5.30
admin. basic.6y no 143 94.70
admin. basic.9y yes 42 8.42
admin. basic.9y no 457 91.58
admin. high.school yes 382 11.47
admin. high.school no 2947 88.53
admin. professional.course yes 49 13.50
admin. professional.course no 314 86.50
admin. university.degree yes 823 14.31
admin. university.degree no 4930 85.69
admin. unknown yes 38 15.26
admin. unknown no 211 84.74
blue-collar illiterate no 8 100.00
blue-collar basic.4y yes 123 5.31
blue-collar basic.4y no 2195 94.69
blue-collar basic.6y yes 107 7.50
blue-collar basic.6y no 1319 92.50
blue-collar basic.9y yes 240 6.62
blue-collar basic.9y no 3383 93.38
blue-collar high.school yes 94 10.71
blue-collar high.school no 784 89.29
blue-collar professional.course yes 41 9.05
blue-collar professional.course no 412 90.95
blue-collar university.degree yes 9 9.57
blue-collar university.degree no 85 90.43
blue-collar unknown yes 24 5.29
blue-collar unknown no 430 94.71
entrepreneur illiterate yes 1 50.00
entrepreneur illiterate no 1 50.00如何将rel.freq数据添加到我的第一个绘图中?
我试过的是:
- 计算每个地点的观察次数
- 按填比例
但不知何故,它解释了如何根据“初始”类别之一,而不是第三种类别来显示比例。
编辑:在与@Nathan交流后,他为我指明了一个更好的方向,我设法做到了以下几点:
{kind=link}
回答 1
Stack Overflow用户
发布于 2016-12-20 13:49:11
把geom_count抛在脑后,用一个新的专栏来做它正在做的事情:
# added a few new rows for multiple jobs
job education y/n q rel.freq
admin. illiterate no 1 100.00
admin. basic.4y yes 10 12.99
admin. basic.4y no 67 87.01
admin. basic.6y yes 8 5.30
admin. basic.6y no 143 94.70
admin. basic.9y yes 42 8.42
tech basic.9y no 22 10
tech basic.4y no 58 50也许你想让sum(q)在这里:
# this is all geom_count really does but it's ornery with aes(fill)
data_big <- data_big %>% group_by(education, job) %>% mutate(cnt = sum(q))
# color for effect
ggplot(data=data_big, aes(job, education)) +
geom_point(aes(size = cnt, fill = rel.freq),shape = 21) +
scale_size_area(max_size = 12, name = "Count")+
scale_fill_distiller(palette = "RdBu", name = "Rel.Freq") +
theme_bw()+
theme(axis.text.x=element_text(angle=45,hjust=1))
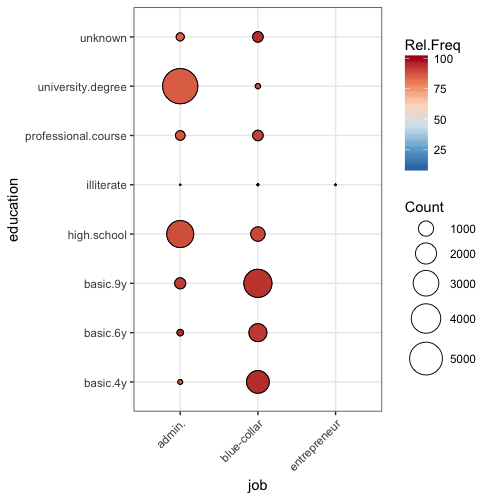
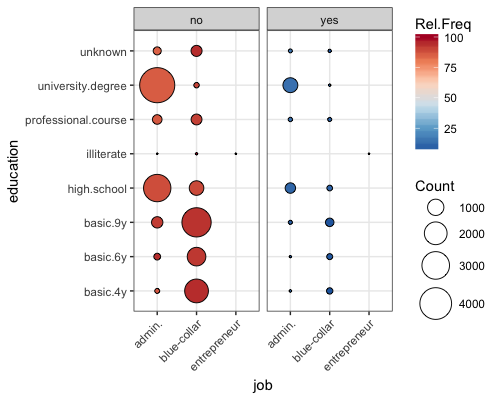
或者,您可以利用面影显示data_big$y/n如下:
data_big <- data_big %>% group_by(education, job, `y/n`) %>% mutate(cnt = sum(q))
ggplot(data=data_big, aes(job, education)) +
geom_point(aes(size = cnt, fill = rel.freq),shape = 21) +
scale_size_area(max_size = 12, name = "Count")+
scale_fill_distiller(palette = "RdBu", name = "Rel.Freq") +
theme_bw()+
facet_wrap(~`y/n`) +
theme(axis.text.x=element_text(angle=45,hjust=1))
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/41241963
复制相关文章
相似问题
腾讯云开发者
