
如何创建频率矩阵?
如何创建频率矩阵?
提问于 2016-12-23 11:27:59
我刚开始使用Python,遇到了以下问题:
假设我有以下列表:
list = [["Word1","Word2","Word2","Word4566"],["Word2", "Word3", "Word4"], ...]我想得到的结果(矩阵)应该如下所示:
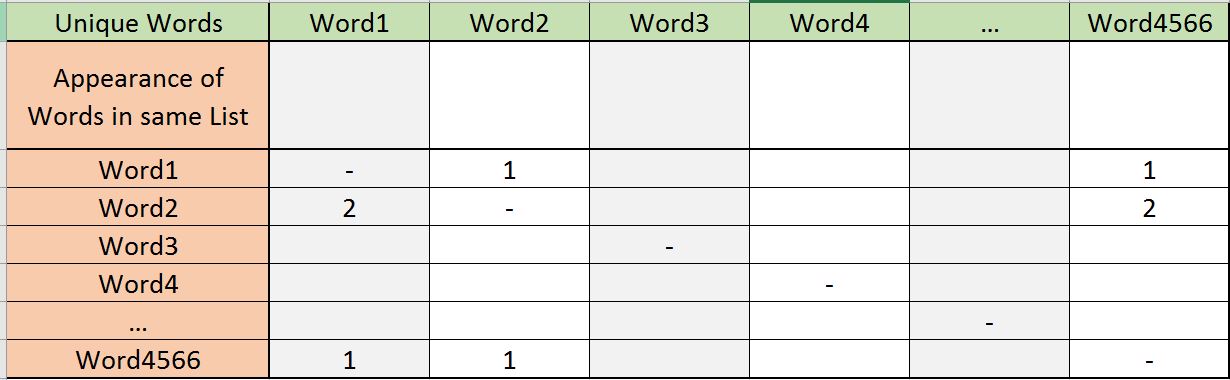
所显示的列和行都显示单词(无论哪个列表)。
我想要的是一个计算每个列表中单词外观的程序(按列表)。
图片是第一个列表之后的结果。
有什么简单的方法可以实现像这样或类似的事情吗?
编辑:基本上,我想要一个列表/矩阵,告诉我当单词1也出现在列表中时,单词2-4566出现了多少次,以此类推。
因此,我会得到一个列表,每一个字,显示所有其他4555字的绝对频率与这个词的关系。
因此,我需要一个算法来迭代所有这些单词列表并构建结果列表。
Stack Overflow用户
发布于 2016-12-23 12:20:50
我觉得很难理解你到底想要什么,但我会尝试做一些假设:
- (1)你有一份清单(A),内载多个字(w)的其他列表(b)。
- (2)对于A-list 中的每个b-列表
- (3)对于b中的每一个w:
- (3.1)计算w在所有b-列表中的总出现次数。
- (3.2)计算w只出现一次的b-列表中有多少个。
- (3)对于b中的每一个w:
如果这些假设是正确的,那么该表就不符合您提供的列表。如果我的假设是错误的,那么我仍然相信我的解决方案可能会给你灵感,或者给你一些如何正确解决它的想法。最后,我不认为我的解决方案是最优的速度或类似。
布斯!!我使用python的内置字典,如果您打算用成千上万的单词填充它们,它们可能会变得非常慢!!看看:https://docs.python.org/2/tutorial/datastructures.html#dictionaries
frq_dict = {} # num of appearances / frequency
uqe_dict = {} # unique
for list_b in list_A:
temp_dict = {}
for word in list_b:
if( word in temp_dict ):
temp_dict[word]+=1
else:
temp_dict[word]=1
# frq is the number of appearances
for word, frq in temp_dict.iteritems():
if( frq > 1 ):
if( word in frq_dict )
frq_dict[word] += frq
else
frq_dict[word] = frq
else:
if( word in uqe_dict )
uqe_dict[word] += 1
else
uqe_dict[word] = 1页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/41300583
复制相关文章
相似问题
腾讯云开发者
