
宾得数据集成(PDI)如何使用postgresql批量加载程序?我的转变永远在运行
我对PDI很陌生,我使用PDI 7,我有6行的excel输入,并希望将它插入到postgresDB中。我的转换是: EXCEL输入-> Postgres批量加载器(仅2步)。
条件1:当我运行转换时,Postgres批量加载,没有停止,也没有将任何东西插入到我的postgresDB中。
条件2:因此,我在Postgres批量加载器之后添加“插入/更新”步骤,以及插入到postgresDB中的所有数据--这意味着成功,但批量加载程序仍在运行。
{kind=link}
从我能得到的所有来源,他们只需要输入和批量装载步骤,在完成转换后,散装装载机是“完成”(我的“运行”)。那么,我想问一下如何为Postgres恰当地解决这个问题?我跳过什么重要的东西了吗?谢谢。
回答 4
Stack Overflow用户
发布于 2017-01-26 08:57:00
我做了一些实验。
环境:
- DB: Postgresv9.5x64
- PDI水壶v5.2.0
- PDI水壶缺陷jvm设置512 PDI
- 数据源: 2_215_000行上的DBF文件
- PDI和Kettle都在同一个本地主机上
- 表在每次运行时被截断
- 每次运行时重新启动PDI Kettle (以避免gc运行的CPU负载过多)
结果在下面帮助你做出决定。
- 批量加载程序:每秒平均超过150_000行的次数约为13-15s。
- 表输出(sql插入):每秒平均11_500行数。总数约为3分18秒。
- 表输出(批处理插入,批处理大小10_000):每秒平均28_000行数。总数约为1分钟30
- 表输出(批处理在5个线程中插入批处理大小3_000):每个线程每秒平均7_600行数。意味着每秒环绕37_000行。总时间约为59秒。
Buld的优点是它不填充jmv的内存,所有数据都会立即流到psql进程中。
表输出用数据填充jvm内存。实际上,在围绕1_600_000行之后,内存已满,并启动了gc。CPU的加载时间高达100%,速度明显减慢。这就是为什么值得使用批处理大小,以找到能提供最佳性能(更大更好)的值,但在某种程度上会导致GC开销。
最后一次实验。提供给jvm的内存足以容纳数据。这可以在变量PENTAHO_DI_JAVA_OPTIONS中进行调整。我将jvm堆大小的值设置为1024 of,并将批处理大小的值增加。
- 表输出(批处理在5个线程中插入批处理大小10_000):每个线程每秒平均12_500行数。意味着每秒60_000行的总数。总时间约为35秒。
现在做决定要容易得多。但是你必须注意到一个事实,那就是水壶pdi和数据库位于同一个主机上。在主机不同的情况下,网络带宽对性能有一定的影响。
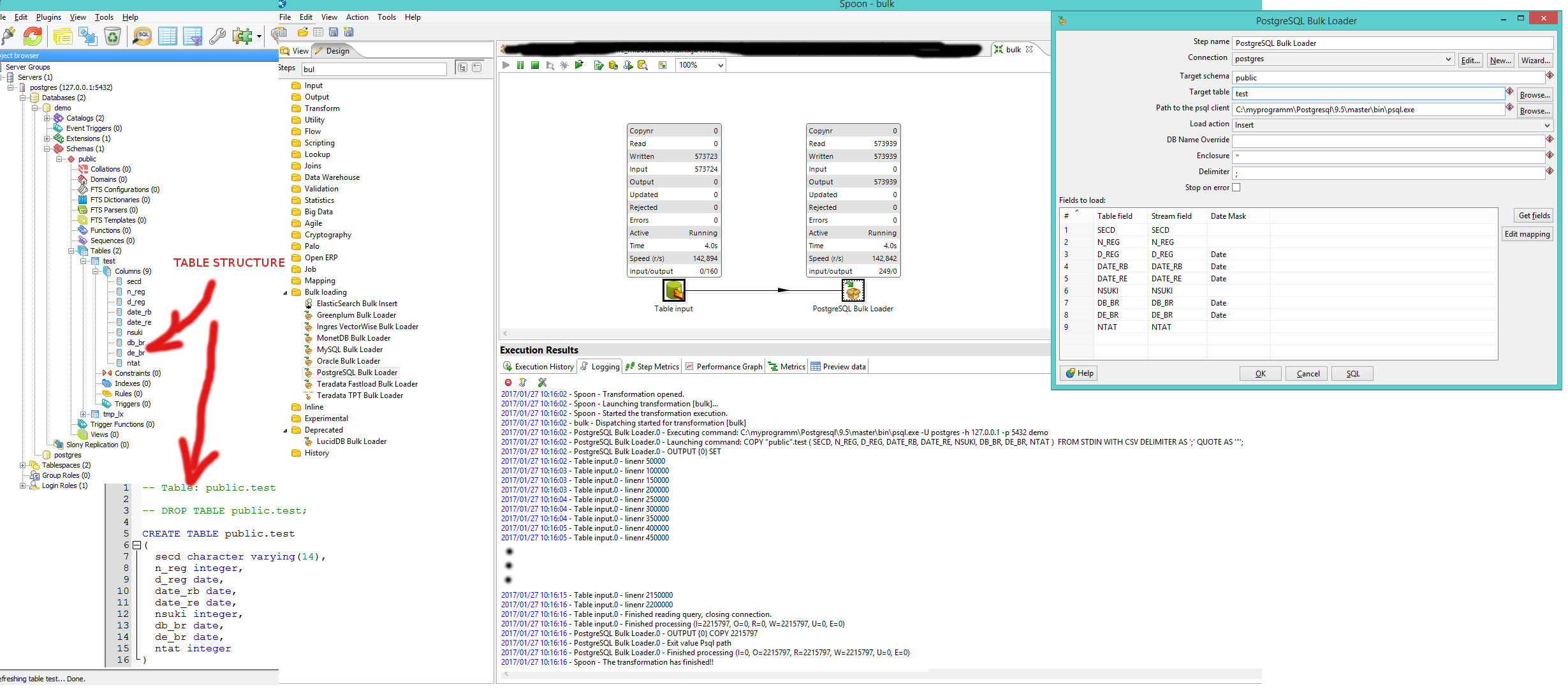
Stack Overflow用户
发布于 2017-01-24 17:18:48
PostgreSQL散装装载机过去只是试验性的。有一段时间没试过了。你确定你需要吗?如果从Excel加载,则不太可能有足够的行来保证使用批量加载器。
只尝试常规的Table Output步骤。如果您只是插入,您也不应该需要Insert/Update步骤。
Stack Overflow用户
发布于 2017-01-25 14:13:24
如果只插入7行,则不需要批量加载程序。大容量装载机设计用来装载大量数据。它使用本地psql客户端。PSQL客户端传输数据的速度要快得多,因为它使用了二进制协议的所有特性,不受jdbc规范的任何限制。JDBC用于其他步骤,如表输出。大多数时间表的输出已经足够了。
Postgres大容量加载程序步骤只是在传入步骤中以csv格式构建内存数据,并将它们传递给psql客户端。
https://stackoverflow.com/questions/41824152
复制相似问题
腾讯云开发者
