
基于贝叶斯优化的深度学习结构超参数优化
构造了一种用于原始信号分类任务的CLDNN (卷积、LSTM、深度神经网络)结构。
每个训练阶段运行约90秒,超量参数似乎很难优化。
本文研究了各种优化超参数的方法(如随机搜索或网格搜索),并对贝叶斯优化进行了研究。
虽然我还没有完全理解优化算法,但我喜欢它对我有很大的帮助。
我想问几个关于优化任务的问题。
- 如何建立关于深度网络的贝叶斯优化?(我们试图优化的成本函数是什么?)
- 我试图优化的功能是什么?它是在N个历元之后的验证集的成本吗?
- 先锋是这个任务的好起点吗?对这项任务还有其他建议吗?
我非常感谢对这个问题的任何见解。
回答 1
Stack Overflow用户
发布于 2017-09-20 09:36:43
虽然我还没有完全理解优化算法,但我喜欢它对我有很大的帮助。
首先,让我简单地解释一下这一部分。贝叶斯优化方法的目的是解决多武装匪徒问题中的勘探开发折衷问题。在这个问题中,存在一个未知的函数,我们可以在任何一点上对其进行评估,但是每个评估成本(直接惩罚或机会成本)都是如此,目标是尽可能少地使用它。基本上,交换条件是:你知道有限点的功能(其中一些是好的,另一些是坏的),所以你可以尝试在当前局部最大值附近的一个区域,希望改进它(开发),或者你可以尝试一个全新的空间区域,它可能会更好或者更糟(探索),或者介于两者之间。
贝叶斯优化方法(如PI,EI,UCB),使用高斯过程 ( GP )建立目标函数模型,并在每一步根据GP模型选择最“有前途”的点(注意,不同的方法可以不同地定义“有前途”)。
下面是一个例子:
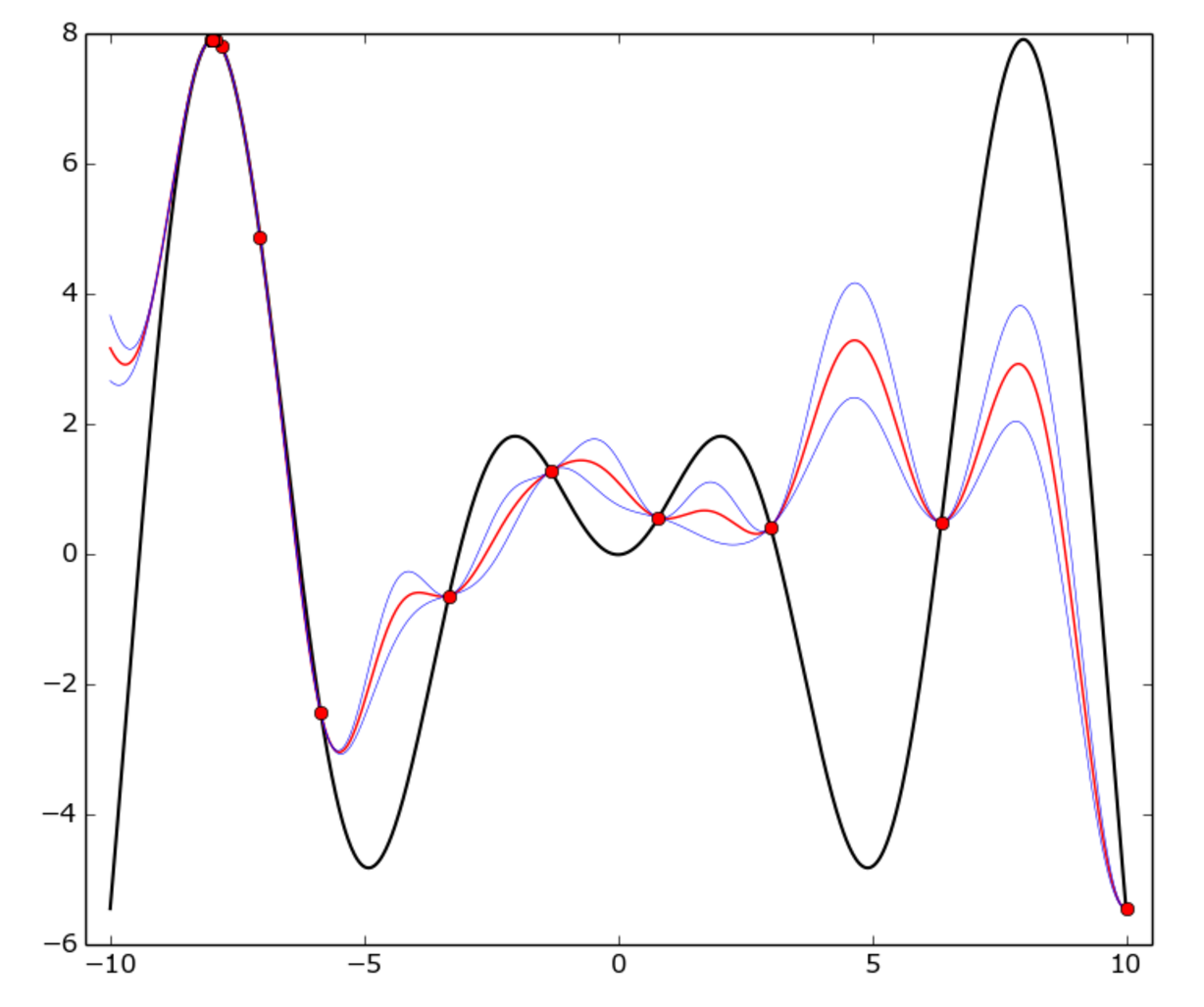
真正的函数是f(x) = x * sin(x) (黑色曲线)在[-10, 10]区间。红点代表每个试验,红色曲线是GP平均值,蓝色曲线是平均正负一个标准差。正如您所看到的,GP模型并不是所有地方都匹配真正的函数,但是优化器很快就确定了-8周围的“热点”区域,并开始利用它。
如何建立关于深度网络的贝叶斯优化?
在这种情况下,空间是由(可能被转换的)超参数定义的,通常是多维单元超立方体。
例如,假设您有三个超参数:学习速率α in [0.001, 0.01]、正则化λ in [0.1, 1] (都是连续的)和隐藏层大小N in [50..100] (整数)。优化的空间是一个三维立方体[0, 1]*[0, 1]*[0, 1].该立方体中的每个点(p0, p1, p2)通过以下转换与三位一体(α, λ, N)相对应:
p0 -> α = 10**(p0-3)
p1 -> λ = 10**(p1-1)
p2 -> N = int(p2*50 + 50)我试图优化的功能是什么?这是N个历元之后的验证集的成本吗?
正确,目标函数是神经网络验证精度。显然,每次评估都是昂贵的,因为它至少需要几个时期的培训。
另外要注意的是,目标函数是随机的,即同一点上的两种评价可能略有不同,但它不是贝叶斯优化的障碍,尽管它明显增加了不确定性。
先锋是这个任务的好起点吗?对这项任务还有其他建议吗?
斯皮尔蒙是一个很好的库,您肯定可以使用它。我也可以推荐超选择。
在我自己的研究中,我编写了自己的小型库,主要有两个原因:我想编写精确的贝叶斯方法来使用(特别是,我发现UCB和PI的投资组合策略收敛速度比其他任何方法都快);此外,还有另一种技术可以节省多达50%的培训时间,称为学习曲线预测 (这个想法是在优化器确信模型学习速度不如其他领域时跳过整个学习周期)。我不知道有哪个库实现了这个功能,所以我自己对它进行了编码,最后它得到了回报。如果您感兴趣,代码是论GitHub。
https://stackoverflow.com/questions/41860817
复制相似问题
腾讯云开发者
