
火花:如何加速foreachRDD?
我们有一个星火流应用程序,它摄取数据@10,000/秒.我们在我们的foreachRDD上使用DStream操作(因为spark不执行,除非它在DStream上找到输出操作)
因此,我们必须使用这样的foreachRDD输出操作,它需要3小时 ...to编写一批数据(10,000),即
CodeSnippet 1:
requestsWithState.foreachRDD { rdd =>
rdd.foreach {
case (topicsTableName, hashKeyTemp, attributeValueUpdate) => {
val client = new AmazonDynamoDBClient()
val request = new UpdateItemRequest(topicsTableName, hashKeyTemp, attributeValueUpdate)
try client.updateItem(request)
catch {
case se: Exception => println("Error executing updateItem!\nTable ", se)
}
}
case null =>
}
}
} 所以我认为foreachRDD内部的代码可能是问题所在,所以注释掉了它,看看花了多少时间.让我感到惊讶的是,在foreachRDD中没有代码的...even仍然运行了3个小时
CodeSnippet 2:
requestsWithState.foreachRDD {
rdd => rdd.foreach {
// No code here still takes a lot of time ( there used to be code but removed it to see if it's any faster without code) //
}
} 请让我们知道,如果我们缺少任何东西或替代的方式来做这一点,我理解,如果没有一个输出操作的DStream火花流应用程序将不会运行。此时我不能使用其他输出操作..。
注意:为了隔离问题并确保发电机代码不是问题
ScreenShot显示了执行的所有阶段和foreachRDD所占用的时间,尽管它是jus循环,内部没有代码
foreachRDD空循环占用的时间
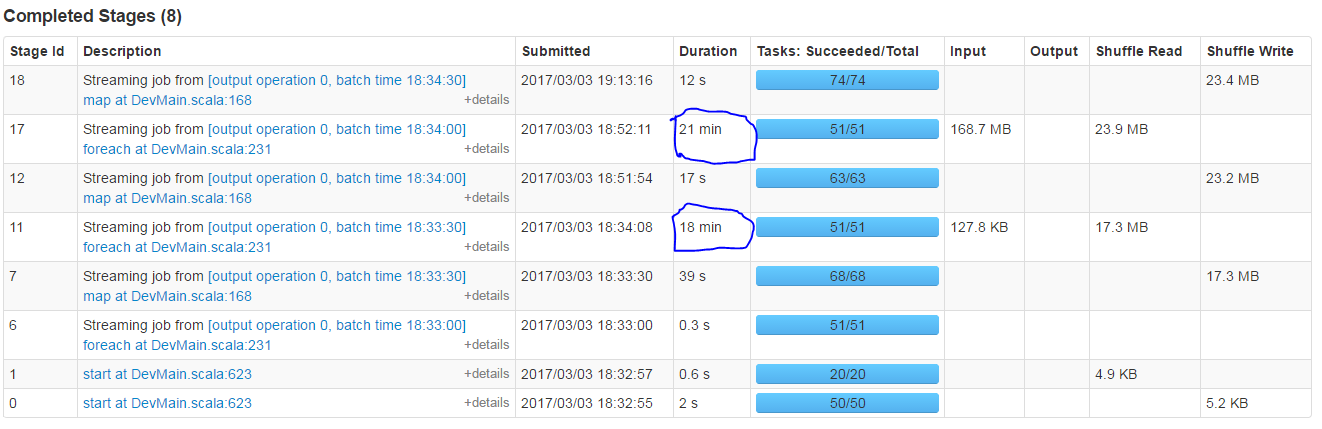
任务分布,用于foreachRDD空循环的9个工作节点之间的大型运行任务.
回答 2
Stack Overflow用户
发布于 2018-12-14 09:11:19
我知道现在已经很晚了,但如果你喜欢听的话,我想这可能会给你一些启发。
不是rdd.foreach内部的代码花费了很长时间,而是rdd.foreach之前的代码,即生成rdd的代码。转换是懒惰的,直到使用结果才能计算它。当代码在rdd.foreach中运行时,spark进行计算,并在rdd.foreach循环中生成数据rows.The代码,只对结果进行操作。您可以通过注释掉rdd.foreach来检查它。
requestsWithState.foreachRDD {
//rdd => rdd.foreach {
// No code here still takes a lot of time ( there used to be code but removed it to //see if it's any faster without code)
//}
} 我想它会非常快,因为没有计算。或者您可以将转换更改为非常简单的转换,它也会很快。它不能解决你的问题,但如果我是对的,它将帮助你找到你的问题。
Stack Overflow用户
发布于 2018-11-21 08:34:06
你试过没有循环,像下面这样吗?
//requestsWithState.foreachRDD {
//rdd => rdd.foreach {
// No code here //
// }
//}这是需要时间的foreachRDD,而不是里面的代码。请注意,这是foreach而不是for。不管里面是否有代码,它都会运行n时间。
有效的测试可以用于性能测试:
https://tech.ovoenergy.com/spark-streaming-in-production-testing/
https://stackoverflow.com/questions/42582542
复制相似问题
腾讯云开发者
