
在目录-R中向文件名添加新字段
在目录-R中向文件名添加新字段
提问于 2017-03-26 17:20:17
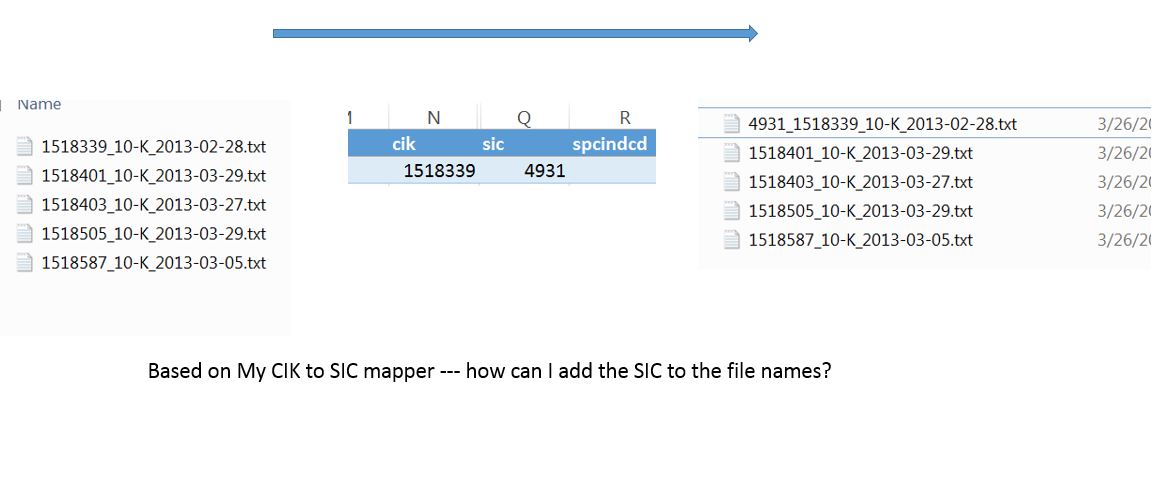
我正在使用R.中的EDGAR包从SEC网站上删除10 Ks,幸运的是,文本文件附带了一致的文件命名约定: CIK编号(这是唯一的归档ID)_File type_Date。
最后,我想由SIC /行业组来分析这些信息,所以我认为最好的方法是将SIC行业代码添加到这个文件名规则中。
下面是我想要做的事情的图片。这有点像一个数据库连接,除了我的文件名将接受新的字段。不知道怎么做,我对R和文件脚本非常陌生。
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-03-26 17:40:29
我假设您有一个带有列data.frame的filenames。(或包含所有文件名的向量)请参见下面的代码:
# A data.frame with a character column 'filenames'
df$CIK <- sapply(df$filenames, FUN = function(x) {unlist(strsplit(x, split = "_"))[1]})
df$CIK <- as.character(df$CIK)现在,让我们假设您有另一个data.frame,它有两列:CIK和SIC。
# A data.frame with two character columns: 'CIK' and 'SIC'
# df2.
#
# We add another column to the first data.frame: 'new_filenames'
df$new_filename <- sapply(1:nrow(df), FUN = function(idx, CIK, filenames, df2) {
SIC <- df2$SIC[which(df2$CIK == CIK[idx])]
new_filename <- as.character(paste(SIC, "_", filenames[idx], sep = ""))
new_filenames
}, CIK = df$CIK, filenames = df$filenames, df2 = df2)
# Now the new filenames are available in df$new_filenames
View(df)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/43032035
复制相关文章
相似问题
腾讯云开发者
