
策略迭代与值迭代
在强化学习中,我试图理解策略迭代和价值迭代之间的区别。这方面有一些一般性的答案,但我有两个具体的问题,我找不到答案。
1)我听说政策迭代“向前工作”,而价值迭代“向后工作”。这是什么意思?我认为这两种方法只需取每一种状态,然后查看它所能达到的所有其他状态,并从中计算值--要么将策略的动作分布(策略迭代)边缘化,要么通过对动作值(值迭代)的讨论。那么,为什么每种方法都“移动”的“方向”有什么概念呢?
2)策略迭代需要在策略评估过程中进行迭代,以求值函数--但是,值迭代只需要一步。为什么这不一样?为什么值迭代只在一步就收敛了?
谢谢!
回答 2
Stack Overflow用户
发布于 2017-05-03 08:41:00
@Nick提供的答案是正确且相当完整的,但是我想添加一个关于值迭代和Policy迭代之间的区别的图形解释,这可能有助于回答您问题的第二部分。
这两种方法,PI和VI,都遵循基于广义策略迭代的相同工作原理。这基本上意味着它们在改进策略(这需要知道它的值函数)和计算新的、改进的策略的值函数之间进行交替。
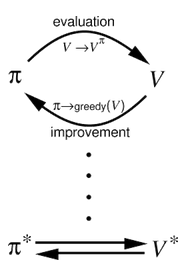
在这个迭代过程的末尾,值和策略都收敛到最优。
然而,人们注意到,不需要精确地计算全值函数,而是需要一个步骤来允许收敛。在下图中,(b)表示由Policy迭代执行的操作,其中计算了全部值函数。而(d)则显示了值迭代是如何工作的。

显然,这两种方法的表达都是简单的,但它突出了每种算法背后的关键思想之间的区别。
Stack Overflow用户
发布于 2017-05-02 06:03:48
我听说政策迭代“向前工作”,而价值迭代“向后工作”。这是什么意思?
我在网上找不到任何用方向描述策略迭代和价值迭代的方法,据我所知,这并不是解释它们之间差异的常见方法。
一种可能是,有人指的是在价值迭代中传播的价值观的视觉印象。在第一次扫描后,值在一个时间步长范围内是正确的。每个值都正确地告诉你,如果你有1步活的话,该怎么做才能最大限度地增加你的累积回报。这意味着,向终端状态的转换和获得奖励具有正值,而大多数其他内容都是0。每扫一次,值就会在地平线上长一步就会变得正确。因此,随着视界的扩大,数值从终端状态向起始状态移动。在策略迭代中,不只是将值传播回一步,而是计算当前策略的完整值函数。然后你改进政策并重复一遍。我不能说这有一个向前的内涵,但它肯定缺乏倒退的外观。您可能希望看到类似问题的巴勃罗的回答,以获得另一种解释差异的解释,这些差异可能有助于您了解所听到的内容。
也有可能你听说过这种前后向相反的对比,比如一些相关的,但不同的,时态差异学习算法的实现。在这种情况下,方向是指您在更新状态操作值时所看到的方向;转发意味着您需要获得有关未来操作结果的信息,而向后则意味着您只需要有关以前发生的事情的信息。你可以在第二版的第12章中读到这一点。
为什么策略迭代必须做大量的值函数计算,而值迭代似乎只是一个最终是最优的?为什么值迭代只在一步就收敛了?
在政策评估中,我们已经有了一项政策,我们只是在根据它的要求计算采取行动的价值。它反复查看每个状态,并将状态的值移动到策略操作将转换到的状态的值(直到值停止变化,我们认为它已经收敛为止)。这个值函数不是最优的。它之所以有用,是因为我们可以结合策略改进定理来改进策略。提取新策略的代价高昂的过程,它要求我们在状态中最大化操作,这种情况很少发生,而且策略似乎很快就会收敛。因此,即使政策评估步骤看起来很费时,PI实际上是相当快的。
Value迭代只是策略迭代,您只需执行一次策略评估,并同时提取一个新策略(最大化超过动作就是隐式策略提取)。然后,您一次又一次地重复这个迭代提取过程,直到值停止更改为止。这些步骤合并在一起的事实使它在纸面上看起来更简单,但是每次扫描时最大化都是昂贵的,这意味着值迭代通常比策略迭代慢。
https://stackoverflow.com/questions/43728781
复制相似问题
腾讯云开发者
