
空页
空页
提问于 2017-05-19 13:25:23
我使用tesseract来检测图像上的字符。
try
{
using (var engine = new TesseractEngine(@"C:\Users\ea\Documents\Visual Studio 2015\Projects\ocrtTest", "eng", EngineMode.Default))
{
using (var img = Pix.LoadFromFile(testImagePath))
{
Bitmap src = (Bitmap)Image.FromFile(testImagePath);
using (var page = engine.Process(img))
{
var text = page.GetHOCRText(1);
File.WriteAllText("test.html", text);
//Console.WriteLine("Text: {0}", text);
//Console.WriteLine("Mean confidence: {0}", page.GetMeanConfidence());
int p = 0;
int l = 0;
int w = 0;
int s = 0;
int counter = 0;
using (var iter = page.GetIterator())
{
iter.Begin();
do
{
do
{
do
{
do
{
do
{
//if (iter.IsAtBeginningOf(PageIteratorLevel.Block))
//{
// logger.Log("New block");
//}
if (iter.IsAtBeginningOf(PageIteratorLevel.Para))
{
p++;//counts paragraph
//logger.Log("New paragraph");
}
if (iter.IsAtBeginningOf(PageIteratorLevel.TextLine))
{
l++;//count lines
//logger.Log("New line");
}
if (iter.IsAtBeginningOf(PageIteratorLevel.Word))
{
w++;//count words
//logger.Log("New word");
}
s++;//count symbols
//logger.Log(iter.GetText(PageIteratorLevel.Symbol));
// get bounding box for symbol
Rect symbolBounds;
if (iter.TryGetBoundingBox(PageIteratorLevel.Symbol, out symbolBounds))
{
Rectangle dueDateRectangle = new Rectangle(symbolBounds.X1, symbolBounds.Y1, symbolBounds.X2 - symbolBounds.X1, symbolBounds.Y2 - symbolBounds.Y1);
rect = dueDateRectangle;
PixelFormat format = src.PixelFormat;
Bitmap cloneBitmap = src.Clone(dueDateRectangle, format);
MemoryStream ms = new MemoryStream();
cloneBitmap.Save(ms, ImageFormat.Png);
ms.Position = 0;
Image i = Image.FromStream(ms);
//i.Save(ms,System.Drawing.Imaging.ImageFormat.Png);
i.Save("character" + counter + ".bmp", ImageFormat.Png);
counter++;
}
} while (iter.Next(PageIteratorLevel.Word, PageIteratorLevel.Symbol));
// DO any word post processing here (e.g. group symbols by word)
} while (iter.Next(PageIteratorLevel.TextLine, PageIteratorLevel.Word));
} while (iter.Next(PageIteratorLevel.Para, PageIteratorLevel.TextLine));
} while (iter.Next(PageIteratorLevel.Block, PageIteratorLevel.Para));
} while (iter.Next(PageIteratorLevel.Block));
}
Console.WriteLine("Pragraphs = " + p);
Console.WriteLine("Lines = " + l);
Console.WriteLine("Words = " + w);
Console.WriteLine("Symbols = " + s);
}当我有一个包含大量文字的图像时,它会起作用,但当我只有一个字母的图像时,它就不会工作了。
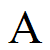
它找到了一个符号,我在输入中看到了它。符号= 1,但它不能得到BoundingBox。为什么?我用的是字母表图像

回答 2
Stack Overflow用户
回答已采纳
发布于 2017-05-20 11:23:51
您可能需要使用不同的OCR和OCR Engine mode进行测试,以获得最佳结果。下面是Tesseract 4.0中可用的使用信息。
Page segmentation modes:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.<br>
OCR Engine modes:
0 Original Tesseract only.
1 Neural nets LSTM only.
2 Tesseract + LSTM.
3 Default, based on what is available.例如,
psm 8只给OCR一个单词就能得到最好的结果psm 6可以给出一个文本块的最佳结果。
在您的代码中,它显示您使用了默认的engine mode,而没有指定segmentation mode。您可以做一些更多的测试,以确定哪些模式给出了正确的结果。
Stack Overflow用户
发布于 2020-10-14 10:16:53
对于下面的图像,请在tesseract命令中使用--psm 9

页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/44071353
复制相关文章
相似问题
腾讯云开发者
