
无法将刮过的结果存储在csv文件中的第三列和第四列中
无法将刮过的结果存储在csv文件中的第三列和第四列中
提问于 2017-05-25 12:13:49
我已经写了一个脚本,是刮地址和电话号码的某些商店,根据名称和盖子。它搜索的方式是从csv文件中分别获取存储在A列和B列中的名称和盖子。但是,在基于搜索获取结果之后,我期望解析器将结果分别放在C列和D列中,如第二张图像所示。在这一点上,我被困住了。我不知道如何使用读写方法操作第三和第四列,以便将数据放在那里。我现在试着用这个:
import csv
import requests
from lxml import html
Names, Lids = [], []
with open("mytu.csv", "r") as f:
reader = csv.DictReader(f)
for line in reader:
Names.append(line["Name"])
Lids.append(line["Lid"])
with open("mytu.csv", "r") as f:
reader = csv.DictReader(f)
for entry in reader:
Page = "https://www.yellowpages.com/los-angeles-ca/mip/{}-{}".format(entry["Name"].replace(" ","-"), entry["Lid"])
response = requests.get(Page)
tree = html.fromstring(response.text)
titles = tree.xpath('//article[contains(@class,"business-card")]')
for title in titles:
Address= title.xpath('.//p[@class="address"]/span/text()')[0]
Contact = title.xpath('.//p[@class="phone"]/text()')[0]
print(Address,Contact)我的csv文件现在是什么样的:
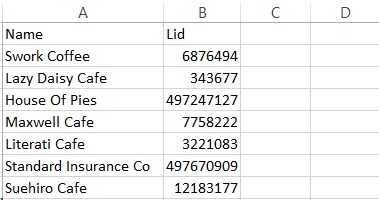
我想要的输出如下:
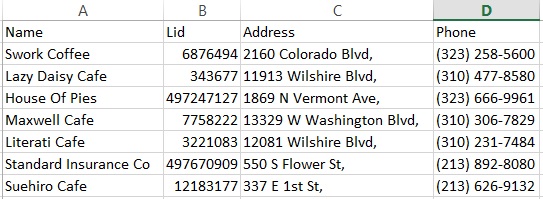
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-05-25 16:18:36
你可以这样做。创建一个新的输出csv文件,其头基于输入csv,并添加两列。当您读取csv行时,它可以作为字典使用,在本例中称为entry。您可以从“网络”收集的内容中将新值添加到本词典中,然后将新创建的行写到文件中。
import csv
import requests
from lxml import html
with open("mytu.csv", "r") as f, open('new_mytu.csv', 'w', newline='') as g:
reader = csv.DictReader(f)
newfieldnames = reader.fieldnames + ['Address', 'Phone']
writer = csv.writer = csv.DictWriter(g, fieldnames=newfieldnames)
writer.writeheader()
for entry in reader:
Page = "https://www.yellowpages.com/los-angeles-ca/mip/{}-{}".format(entry["Name"].replace(" ","-"), entry["Lid"])
response = requests.get(Page)
tree = html.fromstring(response.text)
titles = tree.xpath('//article[contains(@class,"business-card")]')
#~ for title in titles:
title = titles[0]
Address= title.xpath('.//p[@class="address"]/span/text()')[0]
Contact = title.xpath('.//p[@class="phone"]/text()')[0]
print(Address,Contact)
new_row = entry
new_row['Address'] = Address
new_row['Phone'] = Contact
writer.writerow(new_row)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/44180322
复制相关文章
相似问题
腾讯云开发者
