
为什么使用sparklyr的spark_read_csv将RDD持久化到磁盘?
为什么使用sparklyr的spark_read_csv将RDD持久化到磁盘?
提问于 2017-06-01 13:10:57
我有一个由两个工作人员组成的Spark集群--所有节点都有16 of的RAM。我正在使用带内存= TRUE参数的sparklyr spark_read_csv (下面的代码)从spark_read_csv读取数据,但是尽管内存足够,但大部分数据还是溢出到磁盘上。RStudio服务器安装在与Spark相同的节点上。有任何想法,为什么会发生这种情况,如果这是最优的?我怎么能调音呢?谢谢!
flightsFull <- spark_read_csv(sc, "flights_spark",
path = "/s3fs/mypath/multipleFiles",
header = TRUE,
memory = TRUE,
columns = list(
Year = "character",
Month = "character",
DayofMonth = "character",
DayOfWeek = "character",
DepTime = "character",
CRSDepTime = "character",
ArrTime = "character",
CRSArrTime = "character",
UniqueCarrier = "character",
FlightNum = "character",
TailNum = "character",
ActualElapsedTime = "character",
CRSElapsedTime = "character",
AirTime = "character",
ArrDelay = "character",
DepDelay = "character",
Origin = "character",
Dest = "character",
Distance = "character",
TaxiIn = "character",
TaxiOut = "character",
Cancelled = "character",
CancellationCode = "character",
Diverted = "character",
CarrierDelay = "character",
WeatherDelay = "character",
NASDelay = "character",
SecurityDelay = "character",
LateAircraftDelay = "character"),
infer_schema = FALSE)

编辑:添加配置文件内容
spark-defaults.conf
spark.master=spark://ip-host.eu-west-1.compute.internal:7077
spark.jars=/opt/bluedata/bluedata-dtap.jar
spark.executor.extraClassPath=/opt/bluedata/bluedata-dtap.jar
spark.driver.extraClassPath=/opt/bluedata/bluedata-dtap.jar星星之火-env.sh
SPARK_MASTER_HOST=ip-host.eu-west-1.compute.internal
SPARK_WORKER_CORES=8
SPARK_WORKER_MEMORY=32768mEdit2 -添加了执行程序窗格
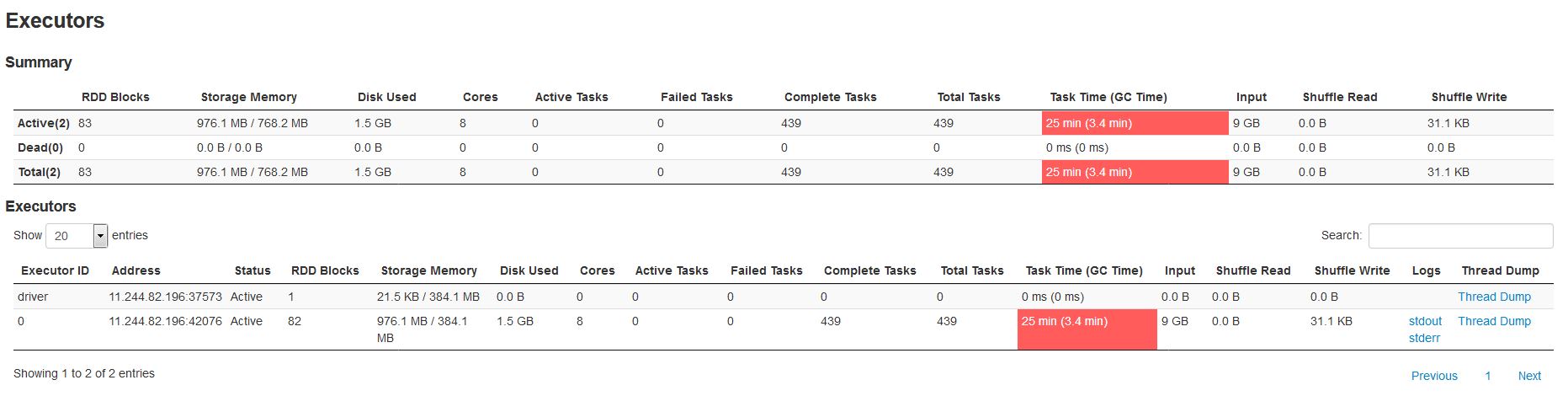
回答 1
Stack Overflow用户
发布于 2017-06-01 17:39:04
我的理解是,您使用默认的内存选项来spark-submit您的星火应用程序,尽管您有足够的内存来使用,但是您不使用。
384.1是您使用完的默认存储内存,因此Spark开始将块持久化到磁盘。
我的理解是,您有一个具有独立主和one独立工作人员的Spark独立集群。这就是spark-env.sh所建议的(没有指定的工人数量),这也是我在屏幕截图中看到的火花执行者的数量,就像火花独立执行人员给出的火花执行者的数量一样。
我的猜测是增加驱动程序和执行器的内存属性,然后重新开始。这将增加内存空间,减少磁盘使用。
我还注意到,所讨论的RDD的存储级别是磁盘序列化的1x,因此sparklyr可以决定设置存储级别本身(给定内存约束)。它通常是由星火开发人员指定的,但是spark_read_csv可能会以某种方式决定它本身。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/44308505
复制相关文章
相似问题
腾讯云开发者
