
如何理解tensorflow在MNIST实验中的技巧?
我是Tensorflow的初学者。我被这个教程弄糊涂了。作者首先给出了一个公式y=softmax(Wx+b),但是在python代码中使用xW+b,并解释了它是一个小技巧。我不明白这个窍门,为什么作者要翻转公式呢?
started/mnist/beginners 首先,我们用表达式tf.matmul(x,W)乘以x乘以W。这是从我们在方程中把它们相乘的时候开始的,我们有Wx,作为处理x的一个小技巧,x是一个多输入的2D张量。然后添加b,最后应用tf.nn.softmax。
回答 3
Stack Overflow用户
发布于 2017-06-29 08:57:40
你可以从公式中看出,
y=softmax(Wx + b)
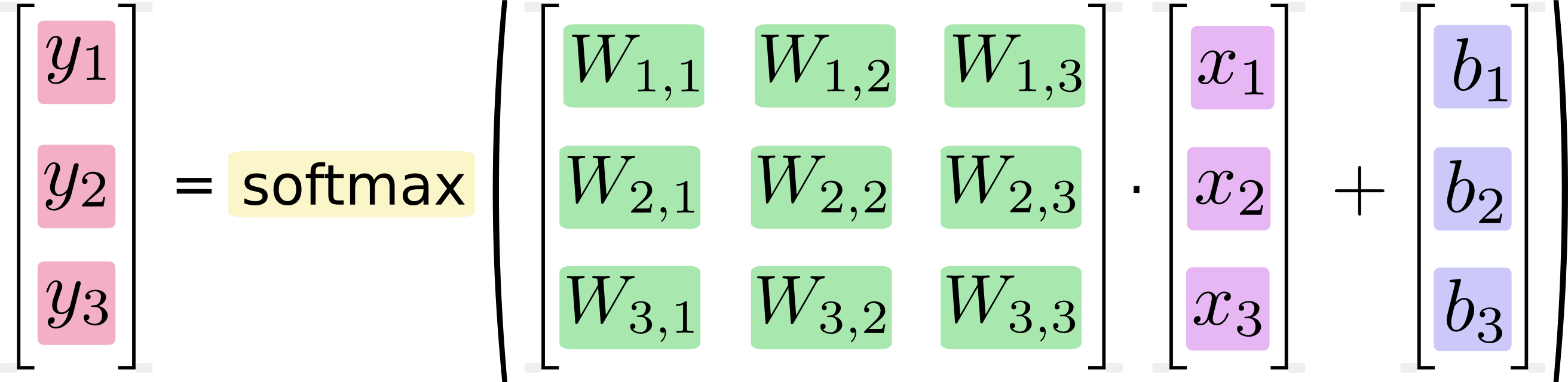
输入x乘以权重变量W,但在doc中
y = tf.nn.softmax(tf.matmul(x, W) + b)为了便于计算,W乘以x,所以我们必须将W从10*784翻转到784*10,与公式保持一致。
Stack Overflow用户
发布于 2017-06-29 09:18:56
一般机器学习(尤指机器学习)。tensorflow,您总是希望您的第一个维度表示您的批处理。诀窍只是一种确保在每个矩阵乘法前后不转移所有东西的方法。
x不是真正的特征列向量,而是形状(batch_size, n_features)的二维矩阵。
如果您保留Wx,那么您将转置x (转到形状的x' of shape (n_features, batch_size)),使用W of shape (n_outputs, n_features),Wx'将是shape (n_outputs, batch_size),所以您必须将其转回(batch_size, n_outputs),这是您最后想要的。
如果您使用的是tf.matmul(x, W),那么W的形状是(n_features, n_outputs ),其结果直接是形状(batch_size, n_outputs)。
Stack Overflow用户
发布于 2017-06-29 09:28:46
我同意这一点一开始还不清楚。
x是具有多个输入的二维张量
非常简洁地告诉你,在tensorflow中,数据存储在张量中,遵循不属于线性代数的惯例。
特别是,最外层的维度(即矩阵的列)总是样本维:也就是说,它的大小与您的样本数相同。
当你将样本特征存储在二维张量(矩阵)中时,这些特征就被存储在最内部的维度,即直线中。也就是说,张量x是方程中变量$x$的转置。W和b也是如此。x.T*W.T=(W.x).T解释了线性代数方程与它的张量实现在乘法中的交换不一致。
https://stackoverflow.com/questions/44820235
复制相似问题
腾讯云开发者
