
用DEAP最小化多目标函数
我试图通过使用德普库最小化自定义函数来执行多目标优化。虽然我在最小化几个目标(目标)时得到了不错的结果,但在超过3或4个目标时,它无法收敛。通常情况下,它会将第一个目标最小化到0,而让其他目标在周围跳跃(而不是最小化)。
我用sci-kit库建立了一个元模型(岭回归)来描述一些模拟数据,所以我的模型是基于系数和拦截(包括在我的代码中)。新的预测建立在150种输入的基础上,这些输入是一致变化的。
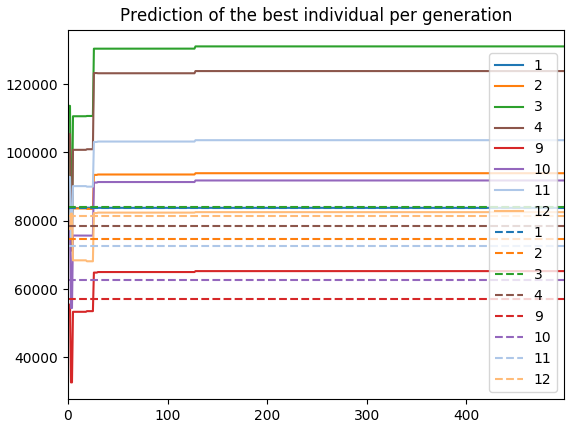
有一个年度选项,最小化3个目标,和一个月选项,最小化8个目标。
我已经将我的代码作为一个gist,因为它很大。这里. --请找
问题:,有人知道剩下的目标不被最小化的原因是什么吗?我试过选择,变异和交叉的过程,但还没有运气。或者它可能与模型本身有关?我也尝试了不同的体重,但由于某些原因,似乎没有什么区别。
该年的目标是:
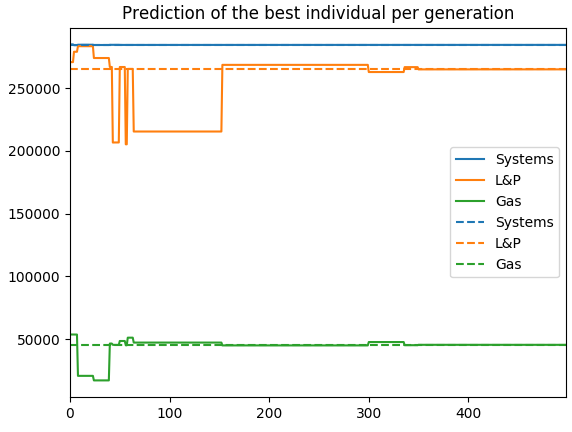
每月目标的结果:
回答 2
Stack Overflow用户
发布于 2017-09-08 11:38:43
只是为了回答我自己的问题。
在评估过程中,我似乎没有返回正确的值。
改变到RMSE的差异,而不是目标和预测之间的绝对差异,起到了关键作用:
def EvaluateObjective(individual):
prediction = calculate(individual, for_sensitivity)
prediction = [int(i) for i in prediction]
# diff = []
# for y in range(len(targets)):
# output = math.sqrt((targets[y] - prediction[y]) ** 2)
# #output = abs(targets[y] - prediction[y])
# diff.append(output)
rmse = np.sqrt((sum((i - j)**2 for i, j in zip(prediction, targets)) / len(targets)))
return (rmse,)
Stack Overflow用户
发布于 2017-12-25 02:31:14
你给了我解决我一直在努力解决的问题。不错的方法,一个小窍门使我的程序也工作!
我敢肯定,一定有很多deap用户像我一样尝试使用两个以上的权重,比如weights=(-1.0,-1.0,1.0)。
我将张贴3个参数的简单例子(2个参数最小化,1个参数最大化)。
- 该示例是关于“如何在最大重量、最大大小的条件下尽可能多地加载项目”。
- 条件:
1. Minimize weight sum.
2. Minimize size sum.
3. Maximize a sum of values.
from numpy import array
import numpy
import random
from deap import base, creator, tools, algorithms
### Multi-objective Optimization Problem ###
IND_INIT_SIZE = 5
MAX_WEIGHT = 2000 # kg
MAX_SIZE = 1500 # m**3
# Create the item dictionary:
r = array([[213, 508, 22], # 1st arg : weight / 2nd arg : size / 3rd arg : value
[594, 354, 50],
[275, 787, 43],
[652, 218, 46],
[728, 183, 43],
[856, 308, 33],
[727, 482, 45],
[762, 683, 26],
[707, 450, 19],
[909, 309, 45],
[979, 247, 42],
[259, 705, 42],
[260, 543, 14],
[899, 825, 17],
[446, 360, 35],
[491, 818, 47],
[647, 404, 17],
[604, 623, 32],
[900, 840, 45],
[374, 127, 33]] )
NBR_ITEMS = r.shape[0]
items = {}
# Create random items and store them in the items' dictionary.
for i in range(NBR_ITEMS):
items[i] = ( r[i][0] , r[i][1] , r[i][2] )
creator.create("Fitness", base.Fitness, weights=(-1.0, 1.0 )) # Note here <- I used only two weights! (at first, I tried weights=(-1.0 , -1.0, 1.0)) but it crashes. With deap, you cannot do such a thing.
creator.create("Individual", set, fitness=creator.Fitness)
toolbox = base.Toolbox()
# Attribute generator
toolbox.register("attr_item", random.randrange, NBR_ITEMS)
# Structure initializers
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_item, n=IND_INIT_SIZE) #
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
def evaluation(individual):
weight = 0.0
size =0.0
value = 0.0
# Maximize or Minimize Conditions
for item in individual:
weight += items[item][0] # It must be minimized.
size += items[item][1] # It must be minimized.
value += items[item][2] # It must be maximized.
# Limit Conditions
if weight > MAX_WEIGHT or size > MAX_SIZE:
return 10000, 0
if value == 0:
value = 0.0000001
MinFitess_score = weight + size # NOTE : Minimize weight, size
MaxFitenss_score = value # NOTE : Maximize weight, size
return MinFitess_score , MaxFitenss_score,
def cxSet(ind1, ind2):
"""Apply a crossover operation on input sets. The first child is the
intersection of the two sets, the second child is the difference of the
two sets.
"""
temp = set(ind1) # Used in order to keep type
ind1 &= ind2 # Intersection (inplace)
ind2 ^= temp # Symmetric Difference (inplace)
return ind1, ind2
def mutSet(individual):
"""Mutation that pops or add an element."""
if random.random() < 0.5:
if len(individual) > 0: # We cannot pop from an empty set
individual.remove(random.choice(sorted(tuple(individual))))
else:
individual.add(random.randrange(NBR_ITEMS))
return individual, # NOTE comma(,) , if there's no comma, an error occurs.
toolbox.register("mate", cxSet)
toolbox.register("mutate", mutSet)
toolbox.register("select", tools.selNSGA2) # NSGA-2 applies to multi-objective problems such as knapsack problem
toolbox.register("evaluate", evaluation)
def main():
ngen = 300 # a number of generation < adjustable value >
pop = toolbox.population(n= 300)
hof = tools.ParetoFront() # a ParetoFront may be used to retrieve the best non dominated individuals of the evolution
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("avg", numpy.mean, axis=0)
stats.register("std", numpy.std, axis=0)
stats.register("min", numpy.min, axis=0)
stats.register("max", numpy.max, axis=0)
algorithms.eaSimple(pop, toolbox, 0.7, 0.2, ngen=ngen, stats=stats, halloffame=hof, verbose=True)
return hof, pop
if __name__ == "__main__":
hof, pop = main()
print(hof) # non-dominated individuals' list # the fittest value is placed on the most right side.理想的结果是:
- 个人({1,2,19,4})或
- 个人({1,2,19,3})
因为他们的总分非常相似。你会得到其中一个结果。
https://stackoverflow.com/questions/44929118
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号