
我的python代码一般都很慢,这正常吗?
我最近开始自学python,并一直在使用这门语言进行在线算法课程。由于某些原因,我为本课程创建的许多代码非常慢(相对于我在过去创建的C/C++ Matlab代码而言),而且我开始担心我没有正确地使用python。
这里有一个简单的python和matlab代码来比较它们的速度。
MATLAB
for i = 1:100000000
a = 1 + 1
end Python
for i in list(range(0, 100000000)):
a=1 + 1matlab代码大约需要0.3秒,python代码大约需要7秒。这是正常的吗?我针对许多复杂问题编写的python代码非常慢。例如,作为一个HW任务,我首先对一个大约有900000个节点的图进行深度搜索,这需要花费很长时间。谢谢。
回答 3
Stack Overflow用户
发布于 2017-07-09 09:48:38
性能为不是Python的明确设计目标
不要过于担心性能--计划在以后需要时进行优化。
这是Python与许多高性能计算后端引擎(如numpy、OpenBLAS甚至库达 )集成的原因之一,仅举几个例子。
如果您想要提高性能,最好的方法是让高性能的库为您做重担。优化Python中的循环(在Python2.7中使用xrange而不是range )不会得到非常显著的结果。
下面是比较不同方法的一些代码:
- 你原来的
list(range()) xrange()的应用建议- 将
i排除在外 - 使用numpy来执行使用numpy数组的加法(向量加法)
- 利用CUDA在GPU上进行矢量加法
代码:
import timeit
import matplotlib.pyplot as mplplt
iter = 100
testcode = [
"for i in list(range(1000000)): a = 1+1",
"for i in xrange(1000000): a = 1+1",
"for _ in xrange(1000000): a = 1+1",
"import numpy; one = numpy.ones(1000000); a = one+one",
"import pycuda.gpuarray as gpuarray; import pycuda.driver as cuda; import pycuda.autoinit; import numpy;" \
"one_gpu = gpuarray.GPUArray((1000000),numpy.int16); one_gpu.fill(1); a = (one_gpu+one_gpu).get()"
]
labels = ["list(range())", "i in xrange()", "_ in xrange()", "numpy", "numpy and CUDA"]
timings = [timeit.timeit(t, number=iter) for t in testcode]
print labels, timings
label_idx = range(len(labels))
mplplt.bar(label_idx, timings)
mplplt.xticks(label_idx, labels)
mplplt.ylabel('Execution time (sec)')
mplplt.title('Timing of integer addition in python 2.7\n(smaller value is better performance)')
mplplt.show()结果(图)运行在OSX上的Python 2.7.13上:
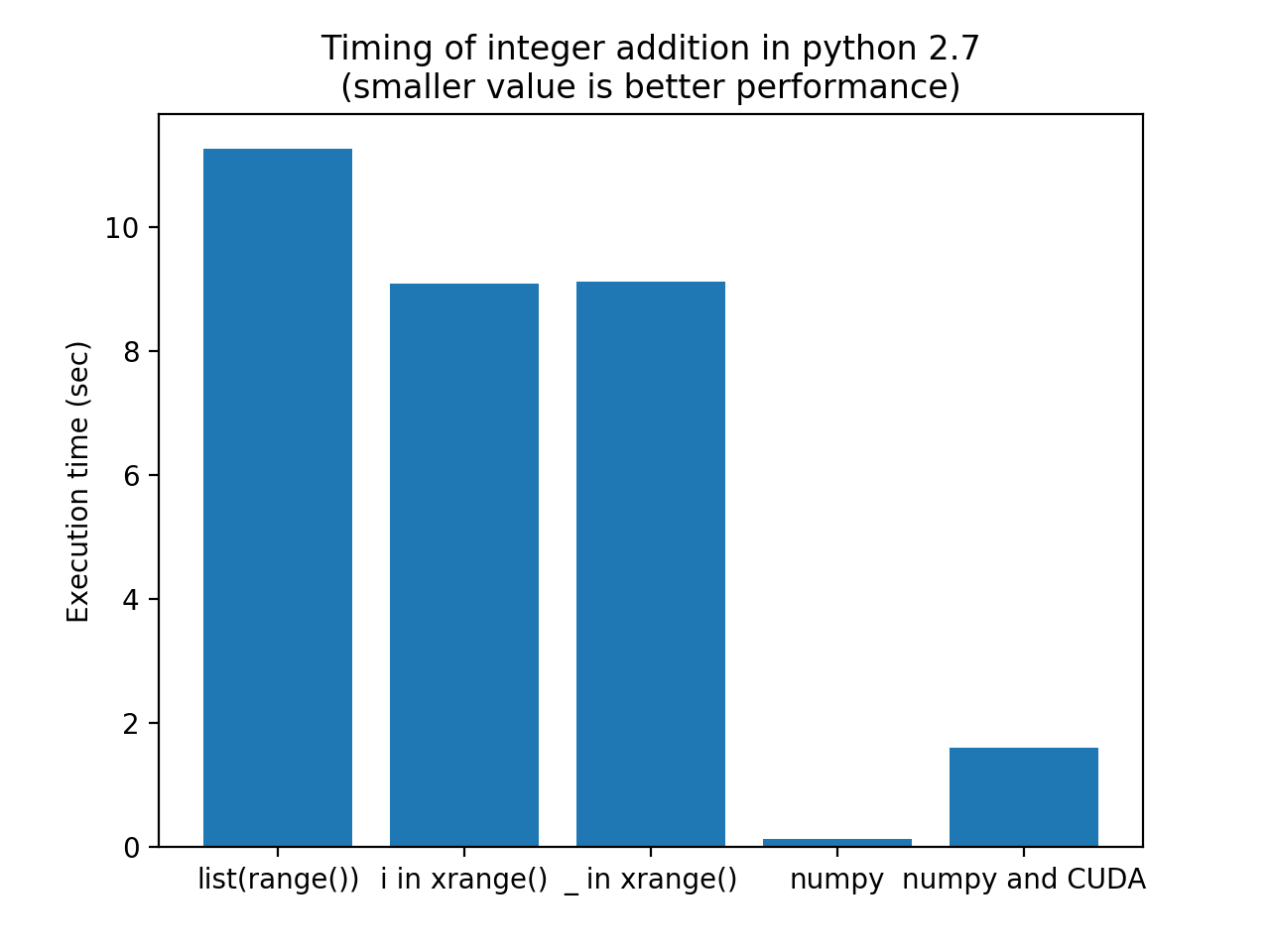
Numpy比CUDA解决方案执行速度快的原因是使用CUDA的开销没有超过Python+Numpy的效率。对于更大的浮点计算,CUDA比Numpy做得更好。
请注意,Numpy解决方案的执行速度比原始解决方案快80倍。如果你的时间是正确的,这甚至比Matlab还要快.
关于DFS的最后一个说明(深度-afirst-搜索):这里是一篇关于Python中DFS的有趣文章。
Stack Overflow用户
发布于 2017-07-09 03:39:31
尝试使用xrange而不是range。
它们之间的区别在于,**xrange**生成值时使用它们而不是range,后者试图在运行时生成静态列表。
Stack Overflow用户
发布于 2017-07-09 03:40:51
不幸的是,python惊人的灵活性和轻松性是以速度慢为代价的。此外,对于如此大的迭代值,我建议使用itertools模块,因为它具有更快的缓存。
xrange是一个很好的解决方案,但是如果您想在字典中迭代等等,最好使用迭代工具,就像这样,您可以遍历任何类型的序列对象。
https://stackoverflow.com/questions/44992717
复制相似问题
腾讯云开发者
