
特征提取类型错误
特征提取类型错误
提问于 2017-07-12 10:05:04
作为编程初学者,我在通过与Scikit学习的机器学习实验对文本进行分类时遇到了一些问题。我使用10倍交叉验证,所以没有部门在火车和测试数据。
我的问题从特征提取模块开始。这是带有错误的代码:
vec = DictVectorizer()
X = vec.fit_transform(instances).toarray()最后一行给出了以下错误:
TypeError: float()参数必须是字符串或数字,而不是'dict‘
实例是一个特征向量字典列表,每个文档都有一个字典。实例列表开头的示例(您可以看到第一个文档的字典的一部分)。
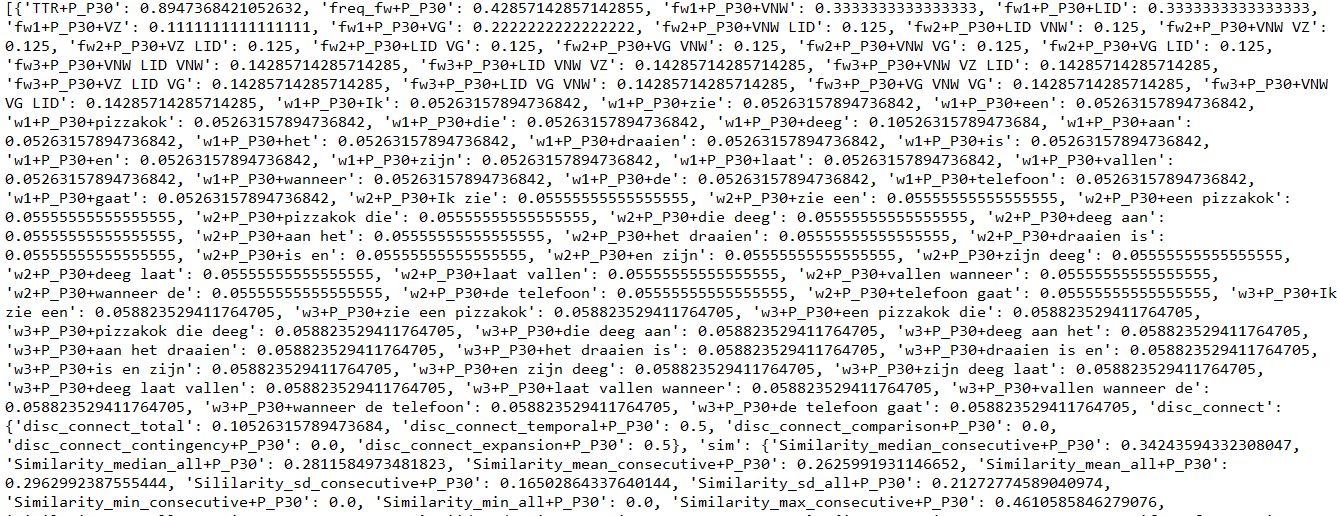
有些特征是嵌套在特征向量字典中的字典。我不知道如何使它不嵌套,但也许这就是问题所在?
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-07-12 19:35:45
是的,问题在于嵌套的字典特征向量。把它们分开,使它们具有独立的特征。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/45054618
复制相关文章
相似问题
腾讯云开发者
