
在字符串匹配和转换为小写时,lower() vs. casefold()
我从谷歌和上面的链接中了解到:lower()和casefold()将把字符串转换为小写,但casefold()甚至会将没有大小写的字母(如德语中的ß )转换为ss。
所有这些都是关于希腊字母的,但我的问题是:
- 还有其他的区别吗?
- 哪一种转换为小写更好?
- 哪一个比较适合检查匹配的字符串?
第2部分:
firstString = "der Fluß"
secondString = "der Fluss"
# ß is equivalent to ss
if firstString.casefold() == secondString.casefold():
print('The strings are equal.')
else:
print('The strings are not equal.')在上面的例子中,我应该使用:
lower() # the result is not equal which make sense to me
或者:
casefold() # which ß is ss and result is the
# strings are equal. (since I am a beginner that still does not
# make sense to me. I see different strings).回答 2
Stack Overflow用户
发布于 2017-08-17 22:20:34
TL;博士
- 纯ASCII文本->
lower() - Unicode文本/用户输入->
casefold()
Casefolding是lower()的一个更激进的版本,它的设置是为了使许多更独特的unicode字符更具有可比性。这是另一种形式的规范化文本,最初可能看起来非常不同,但它考虑到了许多不同语言的字符。
我建议你仔细观察一下折叠的实际情况,所以这里有一个好的开始:W3盒折叠Wiki
要回答另外两个问题,如果你严格使用英语,lower()和casefold()应该产生完全相同的结果。但是,如果您试图使用比我们简单的26个字母字母更多的其他语言来规范文本(只使用ASCII),我将使用casefold()来比较您的字符串,因为它会产生更一致的结果。
另一个来源:Elastic.co箱体折叠
编辑:我最近在这里发现了另一个很好的与一个稍微不同的问题有关的答案 (做一个不区分大小写的字符串比较)。
另一位编辑:@Voo的评论几个月来一直在我脑海中回荡,下面是一些进一步的想法:
正如Voo所提到的,没有任何语言是从不使用标准ASCII值之外的文本的。这就是Unicode存在的原因。考虑到这一点,对我来说,对任何可以包含非ascii值的用户输入的内容使用casefold()更有意义。这可能最终会排除一些可能来自严格处理ASCII的数据库的文本,但一般来说,大多数用户输入可能会使用casefold()来处理,因为它具有正确大写所有字符的逻辑。
另一方面,已知被生成到诸如十六进制UUID之类的ASCII字符空间中的值应该用lower()进行规范化,因为这是一个简单得多的转换。简单地说,lower()将需要更少的内存或更少的时间,因为没有查找,而且它只需要处理26个必须转换的字符。此外,如果您知道您的信息源来自CHAR或VARCHAR ( Server字段)数据库字段,您也可以使用lower,因为Unicode字符不能输入到这些字段中。
所以,这个问题实际上是关于你的数据的来源,当你对用户输入的信息有疑问的时候,只有casefold()。
Stack Overflow用户
发布于 2021-12-11 06:56:52
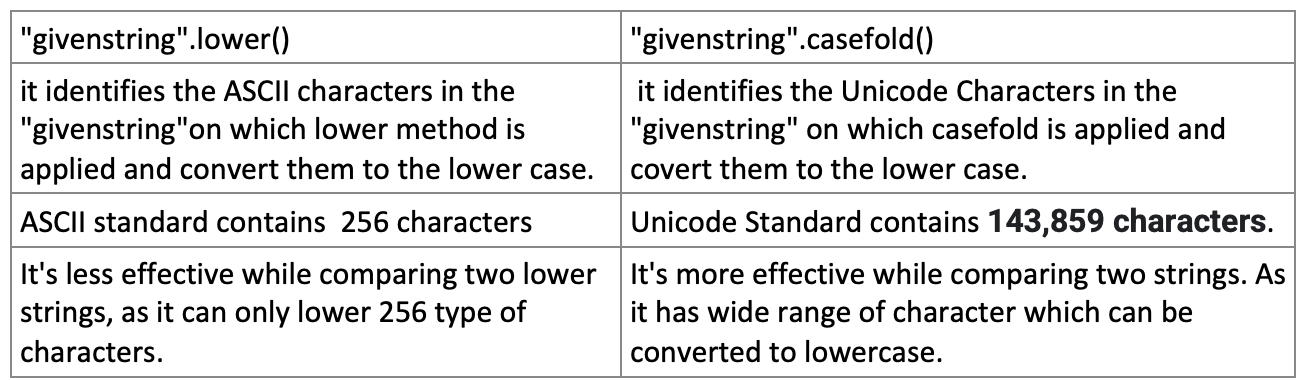
lower() vs casefold()以及何时使用,详情如下.
https://stackoverflow.com/questions/45745661
复制相似问题
腾讯云开发者
