
枚举数据文件中的组
枚举数据文件中的组
提问于 2017-08-18 17:53:26
我有下表
date ui mw maxw tC HL msurp
01/03/2004 A 10 10 eC 0.25 0.1
01/04/2004 A 10 10 eC 0.25 -0.1
01/03/2004 B 20 20 bC 0.5 0.3
01/03/2004 B 20 20 bC 0.25 0.3我想要做的是在这个表中添加一个列,它基本上枚举ui、mw、maxw、tC和HL的唯一组合并枚举
所以,例如在上表中
ui、mw、maxw、tC和HL的独特组合是
A,10, 10, eC, 0.25
B,20, 20, bC, 0.5
B,20, 20, bC, 0.5总共有3,所以输出应该类似于
date ui mw maxw tC HL msurp counter
01/03/2004 A 10 10 eC 0.25 0.1 1
01/04/2004 A 10 10 eC 0.25 -0.1 1
01/03/2004 B 20 20 bC 0.5 0.3 2
01/03/2004 B 20 20 bC 0.25 0.3 3回答 2
Stack Overflow用户
回答已采纳
发布于 2017-08-18 18:25:34
选项1
pd.Series.factorize
df.assign(
counter=df[['ui', 'mw', 'maxw', 'tC', 'HL']].apply(tuple, 1).factorize()[0] + 1)
date ui mw maxw tC HL msurp counter
0 01/03/2004 A 10 10 eC 0.25 0.1 1
1 01/04/2004 A 10 10 eC 0.25 -0.1 1
2 01/03/2004 B 20 20 bC 0.50 0.3 2
3 01/03/2004 B 20 20 bC 0.25 0.3 3选项1.5
选项1的更讨厌的版本,但应该更快
df.assign(
counter=pd.factorize(list(zip(
*[df[c].values.tolist() for c in ['ui', 'mw', 'maxw', 'tC', 'HL']]
)))[0] + 1
)
date ui mw maxw tC HL msurp counter
0 01/03/2004 A 10 10 eC 0.25 0.1 1
1 01/04/2004 A 10 10 eC 0.25 -0.1 1
2 01/03/2004 B 20 20 bC 0.50 0.3 2
3 01/03/2004 B 20 20 bC 0.25 0.3 3选项2
@ayhan的答复(如果他发帖将删除)
df.assign(
counter=df.groupby(['ui', 'mw', 'maxw', 'tC', 'HL']).ngroup() + 1)
date ui mw maxw tC HL msurp counter
0 01/03/2004 A 10 10 eC 0.25 0.1 1
1 01/04/2004 A 10 10 eC 0.25 -0.1 1
2 01/03/2004 B 20 20 bC 0.50 0.3 3
3 01/03/2004 B 20 20 bC 0.25 0.3 2定时
代码如下
(lambda r: r.div(r.min(1), 0).assign(best=lambda x: x.idxmin(1)))(results)
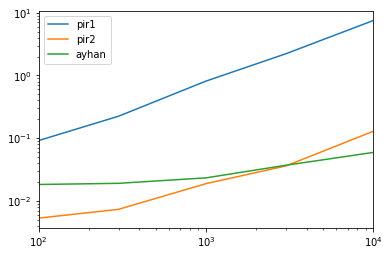
pir1 pir2 ayhan best
100 17.260639 1.000000 3.438354 pir2
300 30.550010 1.000000 2.598456 pir2
1000 43.201163 1.000000 1.236190 pir2
3000 61.593932 1.000000 1.025420 pir2
10000 127.003138 2.177171 1.000000 ayhan
pir1 = lambda d: d.assign(counter=d[['ui', 'mw', 'maxw', 'tC', 'HL']].apply(tuple, 1).factorize()[0] + 1)
pir2 = lambda d: d.assign(counter=pd.factorize(list(zip(*[d[c].values.tolist() for c in ['ui', 'mw', 'maxw', 'tC', 'HL']])))[0] + 1)
ayhan = lambda d: d.assign(counter=d.groupby(['ui', 'mw', 'maxw', 'tC', 'HL']).ngroup() + 1)
results = pd.DataFrame(
index=[100, 300, 1000, 3000, 10000],
columns='pir1 pir2 ayhan'.split(),
dtype=float
)
for i in results.index:
d = pd.concat([df] * i, ignore_index=True)
for j in results.columns:
stmt = '{}(d)'.format(j)
setp = 'from __main__ import d, {}'.format(j)
results.set_value(i, j, timeit(stmt, setp, number=10))
results.plot(loglog=True)Stack Overflow用户
发布于 2017-08-18 18:09:32
就像艾汉的回答一样,假设秩序并不重要
df[['ui','mw','maxw','tC','HL']].T.apply(lambda x : ','.join(x.astype(str))).astype('category').cat.codes
Out[1247]:
0 0
1 0
2 2
3 1
dtype: int8如您所说,我可以按此进行聚合,而不是按[ui、mw、maxw等指定组“。
就这么做,然后groupby('counter')
df['counter']=df[['ui','mw','maxw','tC','HL']].T.apply(lambda x : ','.join(x.astype(str)))页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/45762401
复制相关文章
相似问题
腾讯云开发者
