
用ggplot facet_grid()绘制不同的y轴缩放?
用ggplot facet_grid()绘制不同的y轴缩放?
提问于 2017-09-13 01:01:31
我在用两个独立的y-天平绘制一些数据时遇到了麻烦。这里有两个可视化的一些空气质量数据,我一直在工作。第一个数字描述了每10亿y尺度上的每一个污染物的一部分.在这个图中,co占y轴的主导地位,其他污染物的变化都没有被正确地表示出来。在空气质量科学中,污染物co通常以百万分之比而不是十亿分来表示。第二个图说明了相同的no、no2和o3数据,但我已经将co浓度从ppb转换为ppm (除以1000)。然而,虽然no、no2和o3看起来更好,但co的变化却没有得到公正的表示.
是否有一种简单的方法使用ggplot()来规范y轴的尺度,并且最好地代表每一种污染物?我还试图通过一些其他的例子,利用gridExtra将两个独立的情节缝合在一起,每一个都保留了它们原来的y尺度。
生成这些数字所需的数据是巨大的(26295个观察),所以我仍然在研究一个可重复的例子。希望可以在下面描述的ggplot()代码中找到解决方案:
plt <- ggplot(df, aes(x=date, y = value, color = pollutant)) +
geom_point() +
facet_grid(id~pollutant, labeller = label_both, switch = "y")
plt下面是head(df)的样子(在将co转换为ppm之前):
date id pollutant value
1 2017-06-16 10:00:00 Pohl co 236.00
2 2017-06-16 10:00:00 Pohl no 23.06
3 2017-06-16 10:00:00 Pohl no2 12.05
4 2017-06-16 10:00:00 Pohl o3 8.52
5 2017-06-16 11:00:00 Pohl co 207.00
6 2017-06-16 11:00:00 Pohl no 20.82
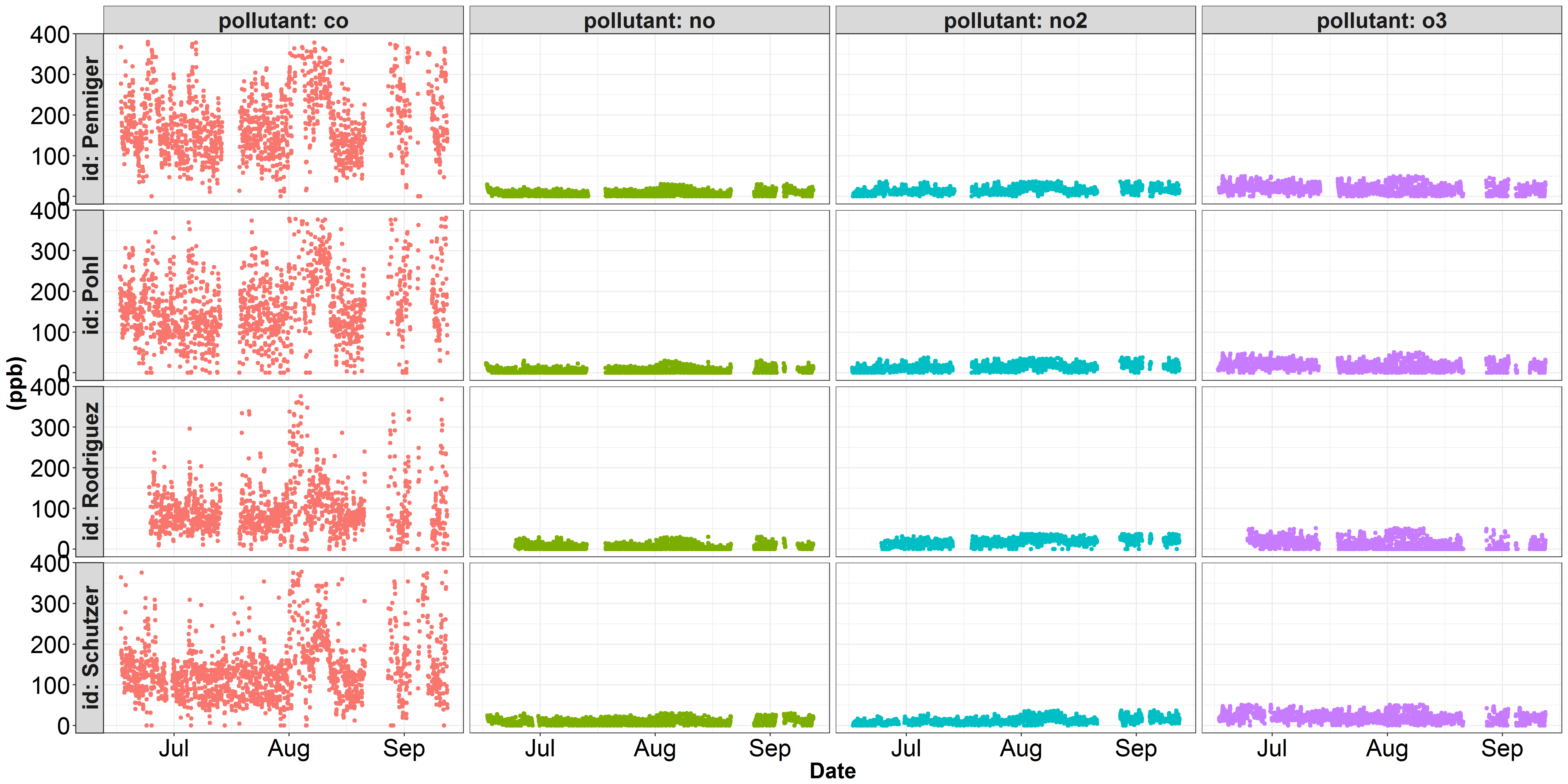
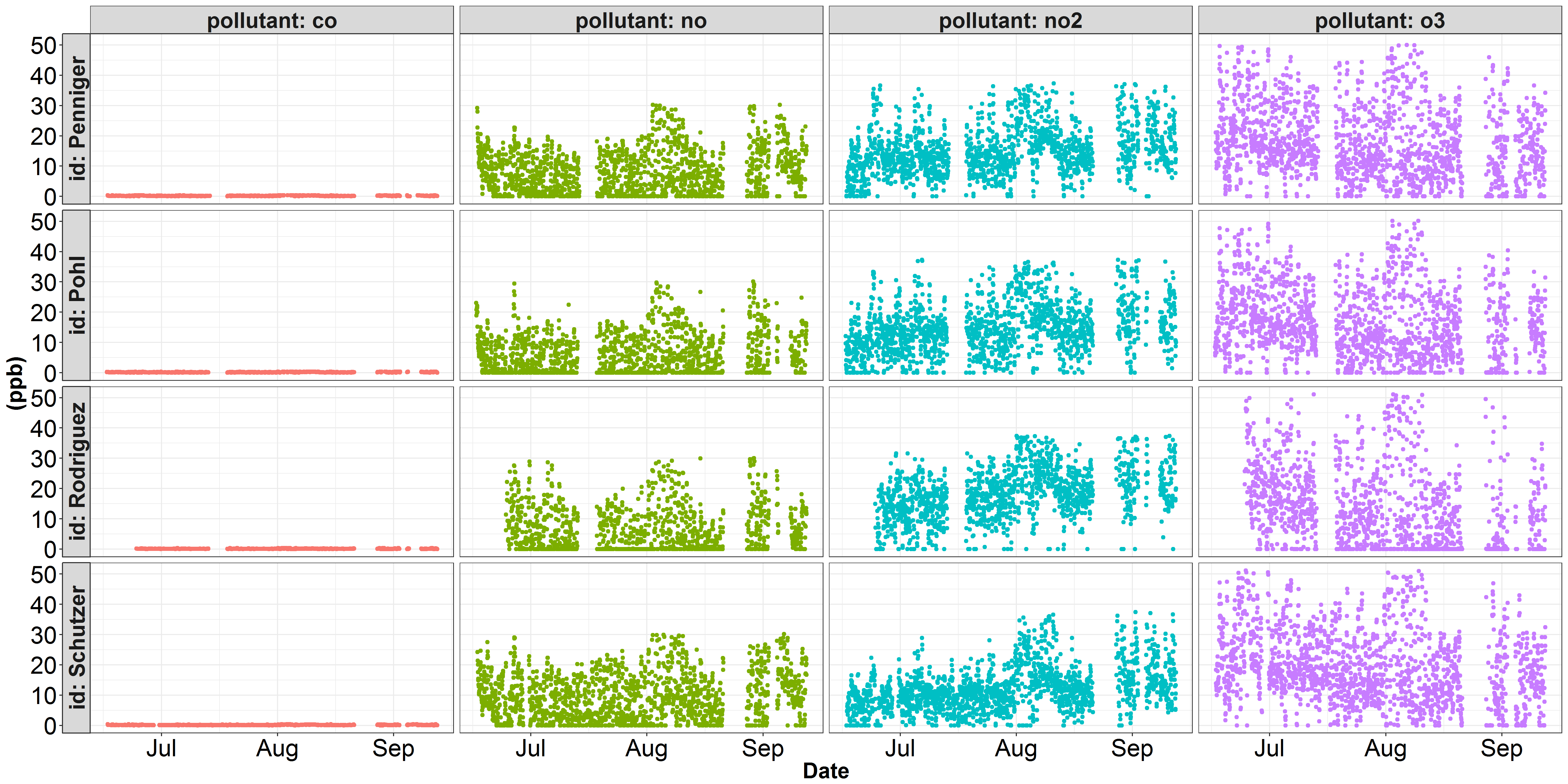
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-09-13 21:13:44
马吕斯指出,在scales = "free_y"函数中包含facet_grid()将提供所需的输出。谢谢!
解决方案:
plt <- ggplot(df, aes(x=date, y = value, color = pollutant)) +
geom_point() +
facet_grid(pollutant~id, scales = "free_y", labeller = label_both, switch = "y")
plt输出:
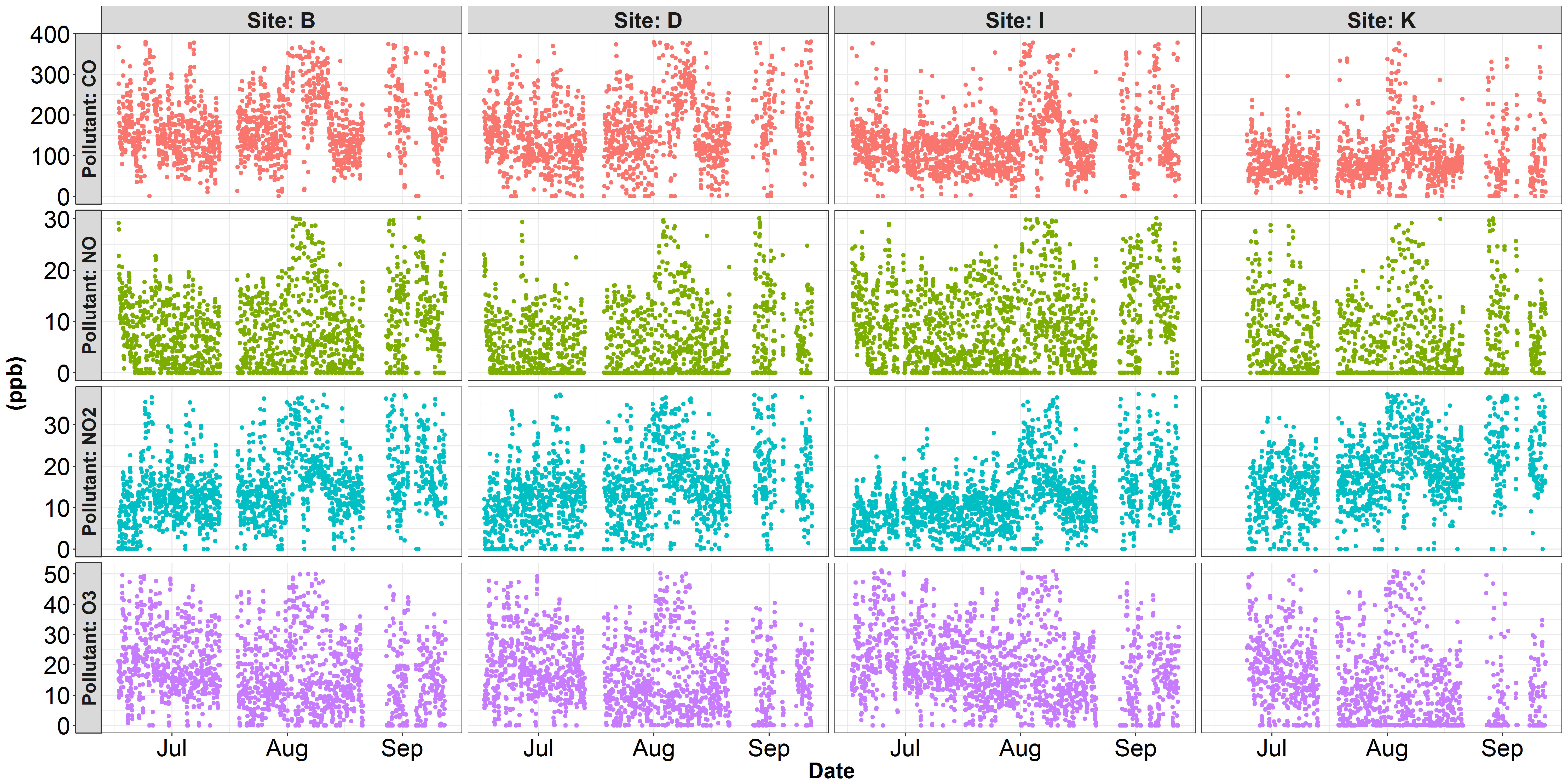
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/46187312
复制相关文章
相似问题
腾讯云开发者
