
删除或不删除存储过程中的临时表
我看到这个问题很多次了,但我无法得到能让我满意的答案。基本上,人们和书籍说的是“虽然临时表在超出范围时被删除,但是当不再需要临时表来减少服务器上的资源需求时,您应该显式地删除它们”。
我非常清楚,当您在management中工作并创建表时,直到您关闭窗口或断开连接为止,您将为该表使用一些资源,从逻辑上讲,最好删除它们。
但是,当您使用过程时,如果您想要清理表,很可能会在它真正结束时进行(我不是说当您在过程中真的不需要时立即删除表的情况)。所以工作流就是这样的:
当你加入SP时:
- 启动SP执行
- 做一些事情
- 落地桌
- 终止执行
据我所知,当你不放弃的时候,它怎么可能起作用:
- 启动SP执行
- 做一些事情
- 终止执行
- 落地桌
这里有什么区别?我只能想象需要一些资源来识别临时表。还有其他想法吗?
更新:
我用两个SP运行了简单的测试:
create procedure test as
begin
create table #temp (a int)
insert into #temp values (1);
drop table #temp;
end还有另一个没有drop语句的。我启用了用户统计并运行了测试:
declare @i int = 0;
while @i < 10000
begin
exec test;
SET @i= @i + 1;
end这就是我所得到的( SP中的试用1-3表,4-6不掉)
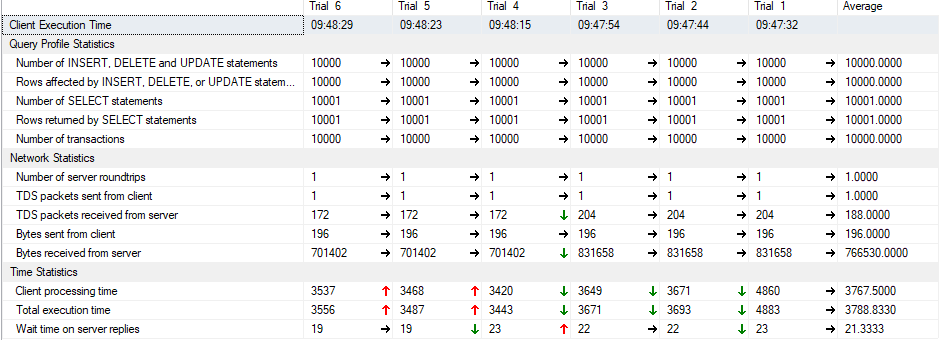
如图所示,当我不删除临时表时,所有的统计数据都是相同的或有所下降。
UPDATE2:
我第二次运行这个测试,但现在有100 k调用,还增加了SET NOCOUNT。以下是研究结果:
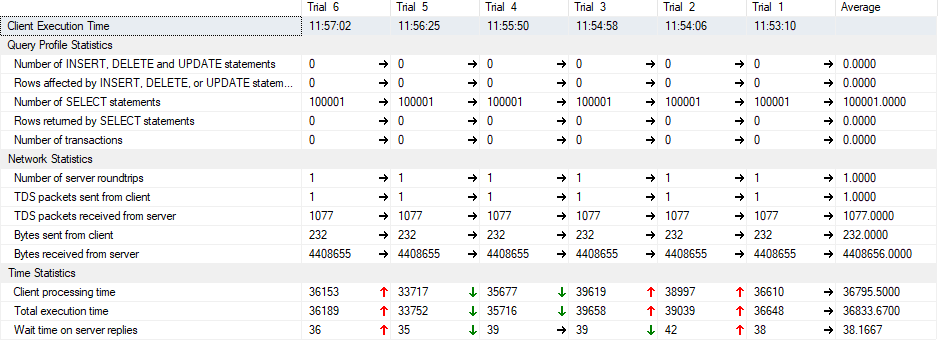
正如第二次运行所确认的那样,如果您不删除SP中的表,那么您实际上节省了一些用户时间,因为这是由其他内部进程完成的,但超出了用户时间。
回答 2
Stack Overflow用户
发布于 2017-09-20 07:47:38
你可以在这篇保罗·怀特的文章中读到更多关于:存储过程中的临时表的文章。
创建并删除,不要 我将在下一篇文章中更详细地讨论这一点,但的关键是,如果临时对象可以缓存,则CREATE和detail不能在存储过程中创建和删除临时表。在执行detail时将临时对象重命名为内部表单,并在下次执行时遇到create时将其重命名为同一个用户可见的名称。此外,临时表上自动创建的任何统计信息也会被缓存。这意味着在下一次调用过程时,来自上一次执行的统计信息仍然保持不变。
Stack Overflow用户
发布于 2017-09-20 06:47:26
从技术上讲,在SPID关闭后,一个本地作用域的临时表(其中一个表前有一个散列标签)将自动退出范围。在一些非常奇怪的情况下,您在某个地方缓存了一个临时表定义,然后没有真正的方法来删除它。通常,当您有一个嵌套的存储过程调用并包含同名的临时表时,就会发生这种情况。
当你完成任务时,放下桌子是个好习惯,但是除非有意想不到的事情发生,否则一旦程序结束,它们就应该被取消范围。
https://stackoverflow.com/questions/46314985
复制相似问题
腾讯云开发者
