
R中Logistic模型解释方向的确定
R中Logistic模型解释方向的确定
提问于 2017-09-29 16:59:10
我试图运行一个logistic回归来预测一个名为has_sed的变量(二进制,描述一个样本是否有沉积物,编码为0=没有沉积物,1=有沉积物)。见下面这个模型的摘要输出:
Call:
glm(formula = has_sed ~ vw + ws_avg + s, family = binomial(link = "logit"),
data = spdata_ss)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.4665 -0.8659 -0.6325 1.1374 2.3407
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.851966 0.667291 1.277 0.201689
vw -0.118140 0.031092 -3.800 0.000145 ***
ws_avg -0.015815 0.008276 -1.911 0.055994 .
s 0.034471 0.019216 1.794 0.072827 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 296.33 on 241 degrees of freedom
Residual deviance: 269.91 on 238 degrees of freedom
AIC: 277.91
Number of Fisher Scoring iterations: 4现在,我理解了一般情况下如何解释逻辑模型的输出,但是我不明白R是如何选择变量的方向的(可能是一个更好的词)。我怎么知道大众汽车的单位增长会增加有沉积物的样本的对数概率,或者增加没有沉淀物的样本的对数概率(即has_sed =0对has_sed = 1)?
我用盒子图画出了每一种关系,而逻辑模型输出中估计值上的符号看起来与我在盒子图中看到的相反。那么,R是计算has_sed的日志概率为0,还是计算它的日志概率为1?
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-09-29 18:00:28
这最好用一个例子来说明,我将使用带有两个类的iris数据。
data(iris)
iris2 = iris[iris$Species!="setosa",]
iris2$Species = factor(iris2$Species)
levels(iris2$Species)
#output[1] "versicolor" "virginica" 让我们做一个glm
model = glm(Species ~ Petal.Length, data = iris2, family = binomial(link = "logit"))
summary(model)
#truncated output
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -43.781 11.110 -3.941 8.12e-05 ***
Petal.Length 9.002 2.283 3.943 8.04e-05 ***
library(ggplot2)
ggplot(iris2)+
geom_boxplot(aes(x = Species, y = Petal.Length))
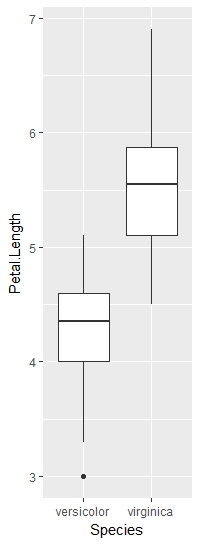
成为“童贞”的几率随着Petal.Length的增加而增加,参考水平是“云芝色”--这是我们做levels(iris2$Species)时的第一个水平。
让我们改变它
iris2$Species = relevel(iris2$Species, ref = "virginica")
levels(iris2$Species)
#output
[1] "virginica" "versicolor"
model2 = glm(Species ~ Petal.Length, data = iris2, family = binomial(link = "logit"))
summary(model2)
#truncated output
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 43.781 11.110 3.941 8.12e-05 ***
Petal.Length -9.002 2.283 -3.943 8.04e-05 ***现在,参考级别是"virginica“-- levels(iris2$Species)中的第一个级别。随着Petal.Length的增加,成为“云母”的几率也随之下降。
简而言之,响应变量中的级别顺序决定了治疗对比的参考级别。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/46493657
复制相关文章
相似问题
腾讯云开发者
