
只包含唯一和不区分大小写的字母的VBscript_Words
只包含唯一和不区分大小写的字母的VBscript_Words
提问于 2017-10-01 12:30:41
我有一个大的文本文件,在其中我需要找到只包含唯一字母的单词(a-z,A-Z)。这些单词不应包含字母以外的任何字符。另外,它需要不区分大小写,这样就不能匹配像alphA、morNing这样的单词.
示例:
marco - Should match(because of unique letters)
asia - Should Not Match(contains 2 'a')
asiA - Should Not Match(as it has 'a' and 'A')
alpha - Should not match
mike - Should match
roger - Should not match
abascus - Should not match
mach1 - Should not match(because of presence of 1) 需要对其进行测试的文件中的文本示例:
将一家公司的stock.The股份分成股份,其总数在业务形成时说明。其他股份随后可由现有股东授权,并由公司发行。在一些法域,每一股股票都有一定的已申报面值,这是一种用于代表公司资产负债表上权益的名义会计价值。然而,在其他法域,股票可以在没有相关面值的情况下发行。 股票代表企业所有权的一小部分。企业可以声明不同类型(或多类)的股票,每种类型都有不同的所有权规则、特权或共享值。股票的所有权可以通过发行股票来记录。股票凭证是一种法律文件,它规定了股东拥有的股份数量,以及股票的其他细节,如票面价值(如果有的话),或者股票的类别。 在联合王国、爱尔兰共和国、南非和澳大利亚,股票也可指完全不同的金融工具,如政府债券,或较不常见的各种有价证券。
我的尝试:
\b(?![^a-zA-Z]+)(?!(?:[a-zA-Z]*([a-zA-Z]))*\1)[a-zA-Z]+\b
但这是这里什么都配不上。
我被困在这里很久了。请给我指出正确的方向。谢谢
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-10-01 12:39:54
试试这个正则表达式:
\b(?![^a-zA-Z]+\b)(?![a-zA-Z]*([a-zA-Z])[a-zA-Z]*\1)[a-zA-Z]+\b
解释:
\b-字边界(?![^a-zA-Z]+\b)-负展望验证单词只应包含1+字母(?![a-zA-Z]*([a-zA-Z])[a-zA-Z]*\1)-另一个负面展望-这部分是为了验证没有2个字母是重复的。进一步拆分如下:[a-zA-Z]*-检查是否存在0+信件([a-zA-Z])-在一个组中捕获一个字母。在组中捕获的这封信将被检查是否有重复。[a-zA-Z]*--再次检查0+字母的存在,以便考虑当重复的信件不在一起时的情况。\1-检查在group1中捕获的信件
[a-zA-Z]+-匹配1+出现的字母\b-字界
VBScript代码:
Option Explicit
Dim objRE, strTest, objMatches, match, strOutput
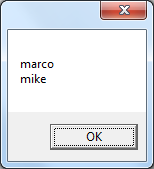
strTest = "marco asia asiA alpha mike roger abascus mach1"
Set objRE = New RegExp
objRE.Global=True
objRE.IgnoreCase=True
objRE.Pattern="\b(?![^a-zA-Z]+\b)(?![a-zA-Z]*([a-zA-Z])[a-zA-Z]*\1)[a-zA-Z]+\b"
Set objMatches = objRE.Execute(strTest)
For Each match In objMatches
strOutput = strOutput & match.Value & vbCrLf
Next
MsgBox strOutput
Set objMatches = Nothing
Set objRE = Nothing输出:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/46512397
复制相关文章
相似问题
腾讯云开发者
