
从图像中删除OCR单词(OpenCV,Python)
从图像中删除OCR单词(OpenCV,Python)
提问于 2017-11-10 15:55:31
所以,从我能开始的..。
我和OCR一起工作。这个剧本很适合我需要的东西。它能准确地检测单词,这对我来说是可以的。
这是结果: 100%的准确性与附加图像。
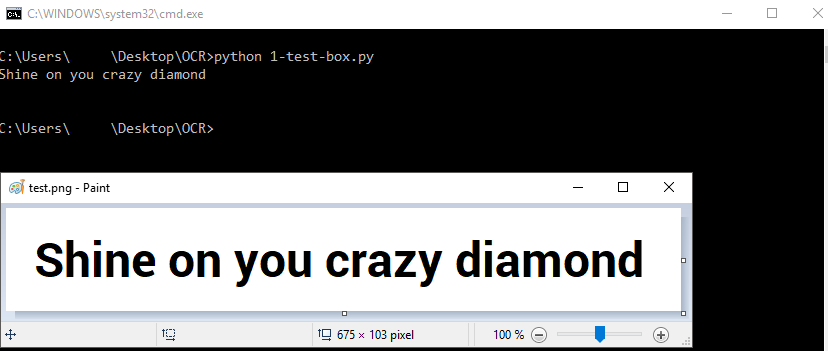
from PIL import Image
import pyocr.builders
import os
os.putenv("TESSDATA_PREFIX", "C:\\Program Files (x86)\\Tesseract-OCR")
tools = pyocr.get_available_tools()
tool = tools[0]
langs = tool.get_available_languages()
lang = langs[0] #eng
file = "test.png"
txt = tool.image_to_string(Image.open(file), lang=lang, builder=pyocr.builders.TextBuilder())
print(txt + '\n')
'''
word = ['SHINE','ON','YOU','CRAZY','DIAMOND','SYD']
if word[2] in txt:
print("## WORD IN LIST ##")
else:
print("## NOT IN LIST ##")'''现在的问题是:如何从图像中删除输出OCR列表中存在的单词(在名为txt的代码中)?我的意思是,如果在控制台(和列表中)中以输出的形式存在“闪耀”这个词,我如何在图像中删除它?或者,如果不移除,创建一个面具让我把它藏起来.
我认为ocr的工作方式是选择文本区域,并在文本周围创建一个边框。在这种情况下,如何删除(甚至显示)这个ROI/边框?在pyocr文档中,有一些关于这个函数的提示(显示边框),但我不知道如何使用它。
如有任何帮助/提示,将不胜感激。
谢谢
编辑:这段代码显示了每个字符的边框
import csv
import cv2
from pytesseract import pytesseract as pt
pt.run_tesseract('test.png', 'output', lang=None, boxes=True, config="hocr")
# To read the coordinates
boxes = []
with open('output.box', 'rt') as f:
reader = csv.reader(f, delimiter = ' ')
for row in reader:
if len(row) == 6:
boxes.append(row)
# Draw the bounding box
img = cv2.imread('test.png')
h, w, _ = img.shape
for b in boxes:
img = cv2.rectangle(img,(int(b[1]),h-int(b[2])),(int(b[3]),h-int(b[4])),(255,0,0),2)
cv2.imshow('output', img)
cv2.waitKey(0)

我怎么才能告诉它只给我看第一个(完整)单词?
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-09-18 23:53:19
这里有一个简单的方法
- 将图像转换为灰度
- Otsu阈值
- 扩张连接等高线
- 查找轮廓并提取每个单词的ROI
- 执行OCR和删除word
在转换成灰度后,我们通过Otsu阈值获得二值图像

接下来,我们将图像倒置并展开,为每个单词形成一个单一的轮廓。

在这里,我们找到轮廓并提取每个单词的ROI。这是检测到的ROIs

我们将每个ROI投到Pytesseract OCR中。如果OCR结果是我们要删除的单词,我们只需将该单词“删除”,只需在ROI中填上白色,并在原始图像中替换它。
使用
words_to_remove = ['on', 'you', 'crazy']结果是

类似于
words_to_remove = ['on', 'you', 'shine', 'diamond']结果是

最后用
words_to_remove = ['on', 'you', 'crazy', 'diamond']

import cv2
import pytesseract
words_to_remove = ['on', 'you', 'crazy', 'diamond']
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
image = cv2.imread("1.png")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5,5))
inverted_thresh = 255 - thresh
dilate = cv2.dilate(inverted_thresh, kernel, iterations=4)
cnts = cv2.findContours(dilate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
for c in cnts:
x,y,w,h = cv2.boundingRect(c)
ROI = thresh[y:y+h, x:x+w]
data = pytesseract.image_to_string(ROI, lang='eng',config='--psm 6').lower()
if data in words_to_remove:
image[y:y+h, x:x+w] = [255,255,255]
cv2.imshow("thresh", thresh)
cv2.imshow("dilate", dilate)
cv2.imshow("image", image)
cv2.waitKey(0)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/47226647
复制相关文章
相似问题
腾讯云开发者
