
Tesseract OCR配置和图像处理
Tesseract OCR配置和图像处理
提问于 2017-12-27 18:20:32
我一直在阅读来自Tesseract .Net包装器的各种图像“类型”的糟糕输出的文章和东西,但是我无法找到解决我的糟糕输出的方法。
下面是我试图解析的图片:
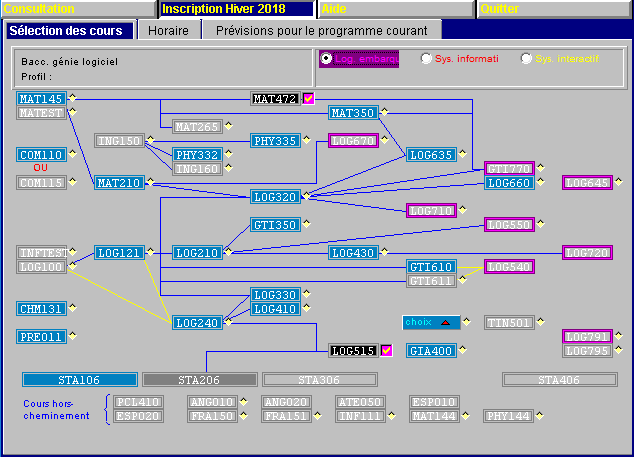
正如你所看到的,有不同的字体,大小,前场和背景。我试着用不同的数量对它进行灰度化和升级,但是没有什么能正确地解析整个图像。
TesseractEngine ocr = new TesseractEngine(Path.Combine(Environment.CurrentDirectory, "tessdata"), "fra", EngineMode.Default);
ocr.SetVariable("tessedit_char_whitelist", "ABCDEFGHIJKLMNOPQRSTUVWXYZÉÈ0123456789:'");
Page pg = ocr.Process(image.ToGrayscale().ScaleByPercent(200));
MessageBox.Show(pg.GetText());有了这段代码(让我知道ToGrayScale()和ScaleByPercent(...)的细节是否有用),下面是我得到的输出:
8300 Q MQ i 09‘0’9 I PIOII‘:
这似乎与Bacc. génie logiciel & Profil :相对应。
尽管如此,我对图像转换知之甚少,所以示例或提示会有很大帮助,但如果有必要,我完全愿意深入了解链接的内容/文档。我应该如何处理这样的图像呢?
编辑:和一些疯子(由@Yves Daoust建议)我已经达到了这一点:
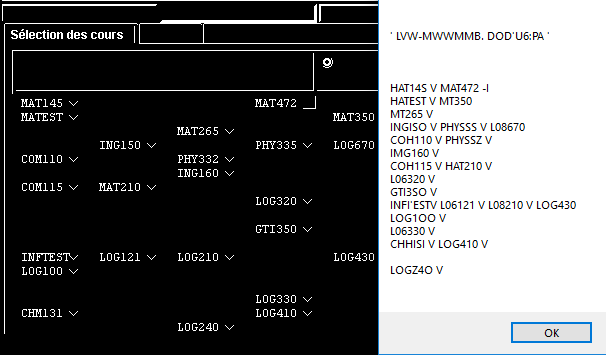
然而,输出(右边)还不是很完美。我一直在努力向Tesseract提供信任,以便它只接受某个列表中的单词。以下是我的尝试:
var initVars = new Dictionary<string, object>() {
{ "load_system_dawg", false },
{ "user_words_suffix", "fra.user-words" },
{ "language_model_penalty_non_freq_dict_word", 1 },
{ "language_model_penalty_non_dict_word", 1 }
};
TesseractEngine ocr = new TesseractEngine(Path.Combine(Environment.CurrentDirectory, "tessdata"), "fra", EngineMode.Default,
Enumerable.Empty<string>(), initVars, false);我一直在寻找关于如何提供这样的信任的例子,但我只找到了简短、不详细的文本解释。
回答 1
Stack Overflow用户
发布于 2017-12-27 22:31:25
您可以在很大程度上帮助Tesseract自己提取字符,这在这里非常简单:只保留白色的像素(以及表单其他部分的其他颜色)。
顺便说一句,字符是如此的可预测,你可以自己进行识别(通过简单的像素比较),而无需借助Tesseract。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/47996883
复制相关文章
相似问题
腾讯云开发者
