
Python--使用YouTube问题对BS4进行抓取描述的请求
Python--使用YouTube问题对BS4进行抓取描述的请求
提问于 2018-01-03 00:48:20
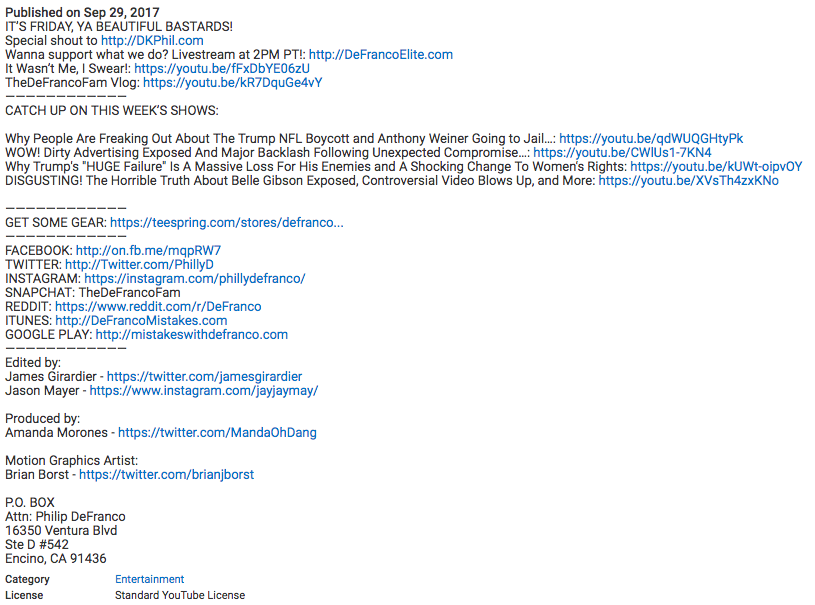
我试图同时得到文本和链接,如图片所示。但我只能通过兄弟姐妹获得文本和之后的链接。我需要他们像想象中那样走到一起。我试过使用br.next_element,但它没有捕获a-链接。我遗漏了什么?
import requests
from bs4 import BeautifulSoup
url_id = 'aM7aW0G58CI'
s = requests.Session()
r = s.get('https://www.youtube.com/watch?v='+url_id)
html = r.text
soup = BeautifulSoup(html, 'lxml')
for i in soup.find_all('p', id='eow-description'):
for br in i.find_all('br'):
next_sib = br.next_sibling
print(next_sib)
for i in soup.find_all('p', id='eow-description'):
for a in i.find_all('a'):
print(a.text)这是我得到的输出。我看不懂下面的截图。
OutPut:
Special shout to
Wanna support what we do? Livestream at 2PM PT!:
It Wasn’t Me, I Swear!:
TheDeFrancoFam Vlog:
————————————
CATCH UP ON THIS WEEK’S SHOWS:
<br/>
Why People Are Freaking Out About The Trump NFL Boycott and Anthony Weiner Going to Jail…:
WOW! Dirty Advertising Exposed And Major Backlash Following Unexpected Compromise…:
Why Trump's "HUGE Failure" Is A Massive Loss For His Enemies and A Shocking Change To Women's Rights:
DISGUSTING! The Horrible Truth About Belle Gibson Exposed, Controversial Video Blows Up, and More:
<br/>
————————————
GET SOME GEAR:
————————————
FACEBOOK:
TWITTER:
INSTAGRAM:
SNAPCHAT: TheDeFrancoFam
REDDIT:
ITUNES:
GOOGLE PLAY:
————————————
Edited by:
James Girardier -
Jason Mayer -
<br/>
Produced by:
Amanda Morones -
<br/>
Motion Graphics Artist:
Brian Borst -
<br/>
P.O. BOX
Attn: Philip DeFranco
16350 Ventura Blvd
Ste D #542
Encino, CA 91436
http://DKPhil.com
http://DeFrancoElite.com
https://youtu.be/fFxDbYE06zU
https://youtu.be/kR7DquGe4vY
https://youtu.be/qdWUQGHtyPk
https://youtu.be/CWlUs1-7KN4
https://youtu.be/kUWt-oipvOY
https://youtu.be/XVsTh4zxKNo
https://teespring.com/stores/defranco...
http://on.fb.me/mqpRW7
http://Twitter.com/PhillyD
https://instagram.com/phillydefranco/
https://www.reddit.com/r/DeFranco
http://DeFrancoMistakes.com
http://mistakeswithdefranco.com
https://twitter.com/jamesgirardier
https://www.instagram.com/jayjaymay/
https://twitter.com/MandaOhDang
https://twitter.com/brianjborst
回答 3
Stack Overflow用户
回答已采纳
发布于 2018-01-03 01:14:26
使用children和检查我创建的tag名称(child.name)
import requests
from bs4 import BeautifulSoup
url_id = 'aM7aW0G58CI'
s = requests.Session()
r = s.get('https://www.youtube.com/watch?v='+url_id)
soup = BeautifulSoup(r.text, 'lxml')
# to concatenate <br>
br = ''
for p in soup.find_all('p', id='eow-description'):
for child in p.children:
if child.name == 'a':
#print(' a:', child.text)
print(br, child.text)
br = '' # reset br
elif child.name == 'br':
if child.next_sibling.name != 'br': # skip <br/> ?
#print('br:', child.next_sibling)
br += str(child.next_sibling)
#else:
# print(child.name, child)我得到:
Special shout to http://DKPhil.com
Wanna support what we do? Livestream at 2PM PT!: http://DeFrancoElite.com
It Wasn’t Me, I Swear!: https://youtu.be/fFxDbYE06zU
TheDeFrancoFam Vlog: https://youtu.be/kR7DquGe4vY
———————————— CATCH UP ON THIS WEEK’S SHOWS: Why People Are Freaking Out About The Trump NFL Boycott and Anthony Weiner Going to Jail…: https://youtu.be/qdWUQGHtyPk
WOW! Dirty Advertising Exposed And Major Backlash Following Unexpected Compromise…: https://youtu.be/CWlUs1-7KN4
Why Trump's "HUGE Failure" Is A Massive Loss For His Enemies and A Shocking Change To Women's Rights: https://youtu.be/kUWt-oipvOY
DISGUSTING! The Horrible Truth About Belle Gibson Exposed, Controversial Video Blows Up, and More: https://youtu.be/XVsTh4zxKNo
————————————GET SOME GEAR: https://teespring.com/stores/defranco...
————————————FACEBOOK: http://on.fb.me/mqpRW7
TWITTER: http://Twitter.com/PhillyD
INSTAGRAM: https://instagram.com/phillydefranco/
SNAPCHAT: TheDeFrancoFamREDDIT: https://www.reddit.com/r/DeFranco
ITUNES: http://DeFrancoMistakes.com
GOOGLE PLAY: http://mistakeswithdefranco.com
————————————Edited by:James Girardier - https://twitter.com/jamesgirardier
Jason Mayer - https://www.instagram.com/jayjaymay/
Produced by:Amanda Morones - https://twitter.com/MandaOhDang
Motion Graphics Artist:Brian Borst - https://twitter.com/brianjborst编辑:您可能需要使用的
else:
print(child.name, child)获取PO框地址
Stack Overflow用户
发布于 2018-01-03 18:08:29
我找到了一个很简单的方法:
for p in soup.find_all('p', id='eow-description'):
print(p.get_text('\n'))现在唯一的问题是有些链接被...剥夺了。
您也可以使用youtube-dl python模块来获得youtube视频的描述。
Stack Overflow用户
发布于 2019-02-19 07:56:15
我找到了这条路..。
import pafy
url='https://www.youtube.com/watch?v=aM7aW0G58CI'
vid=pafy.new(url)
print(vid.description)通过这种方法,您将得到您的内容完全相同的方式显示在Youtube的视频描述。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/48069806
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号