
用stat_frequency计数
我有一个用ggplot创建一些情节的例程:
getPlotList = function(param.list, data=db, y, color){
param.list %>% sapply(function(var){
ggplot(data=data, aes(x=data[[var]], y=data[[y]], color=data[[color]]))+
stat_summary(fun.y = mean, fun.ymin = function(x){mean(x) - sem(x)}, fun.ymax = function(x){mean(x) + sem(x)}, geom = "errorbar", width=.1, position = position_dodge(0.3), na.rm = TRUE) +
stat_summary(fun.y = mean, geom = "point", position = position_dodge(0.3), na.rm = TRUE) +
ylim(0, NA) +
}, simplify = FALSE, USE.NAMES = TRUE)
}我是这样用的:
c("col1", "col2", "col3") %>% getPlotList(y="col4", color="col5")这是完美的(我有几十个情节要写),并给出这样的结果(但没有n=.(标签):
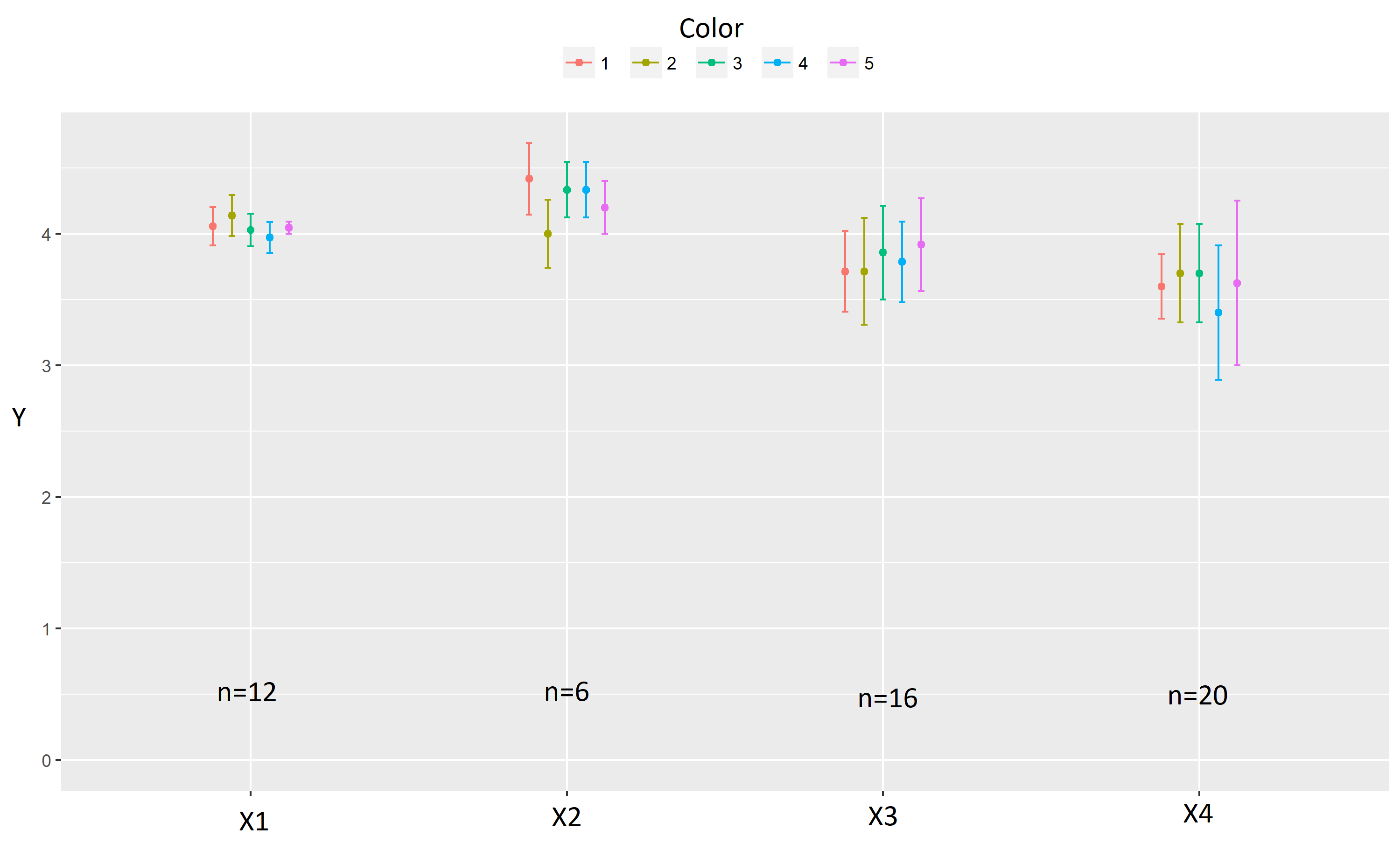
问题是,我的计数对每种颜色都是一样的,但它可以随x而变化。
因为有错误条(它不会显示是n=1还是n=0),所以我必须在标签中显示计数,就像我在图片上所做的那样(用油漆)。
SO上有许多类似的问题(如this one、this one、this one等),但它们都使用geom_hist或geom_bar,它们碰巧都有..count..元可用,与我正在使用的stat_summary不同。
我怎样才能添加那些标签?
PS :我试着用商数代替数据[.]但不幸地失败了。这不是问题的主要部分,但如果有人有想法,这将对我有很大的帮助。
回答 1
Stack Overflow用户
发布于 2018-01-10 16:44:04
这是使用以下示例数据构建的:
sampleData <-
data.frame(
col1 = factor(rep(LETTERS[1:4], c(12, 6, 16, 20)*5)
, levels = LETTERS[1:4])
, col2 = factor(rep(LETTERS[1:4], c(1, 17, 16, 20)*5)
, levels = LETTERS[1:4])
, col3 = factor(rep(LETTERS[1:4], c(0, 18, 16, 20)*5)
, levels = LETTERS[1:4])
, col4 = rnorm(54*5, 4, 2)
, col5 = factor(rep(1:5, 54))
)基本的方法是自己手动添加标签。为此,我使用table来计数每一个X/颜色的出现情况,并生成一个新的data.frame来显示它们。请注意,虽然您说X组中的每种颜色都有相同的样本大小,但最好是防御性地编程。我不相信这个(例如,使用第一个颜色的计数),而是使用apply来获取所有的唯一值。只要只有一个,效果是一样的。然而,如果有多个,这将给你一个指示。
此外,我继续并将映射转换为使用aes_string,这样它就可以通过列标签填充。如果您不喜欢这种行为,只需使用ylab等重写即可。
类似地,没有找到函数sem (我假设它是一个自定义函数),因此我使用了mean_cl_normal函数,这有一个额外的优点,即使用fun.data参数来进行代码的更干净。(我也更喜欢信心区间,而不是仅仅显示SEM,但这更像是风格而不是实质)。
getPlotList = function(param.list, data=db, y, color){
param.list %>% sapply(function(var){
myCounts <- table(data[[var]], data[[color]])
forLabels <-
data.frame(
x = row.names(myCounts)
, label = paste("n =", apply(myCounts, 1, function(x){paste(unique(x), collapse = ";")}))
, y = 0.5
)
ggplot(data=data, aes_string(x=var, y=y, color=color))+
stat_summary(fun.data = mean_cl_normal, position = position_dodge(0.3), na.rm = TRUE) +
stat_summary(fun.y = mean, geom = "point", position = position_dodge(0.3), na.rm = TRUE) +
ylim(0, NA) +
geom_text(aes(x = x, y = y, label = label, color = NA)
, forLabels
, show.legend = FALSE)
}, simplify = FALSE, USE.NAMES = TRUE)
}现在,这个代码:
c("col1", "col2", "col3") %>% getPlotList(y="col4", color="col5", data = sampleData)给出了以下情节:
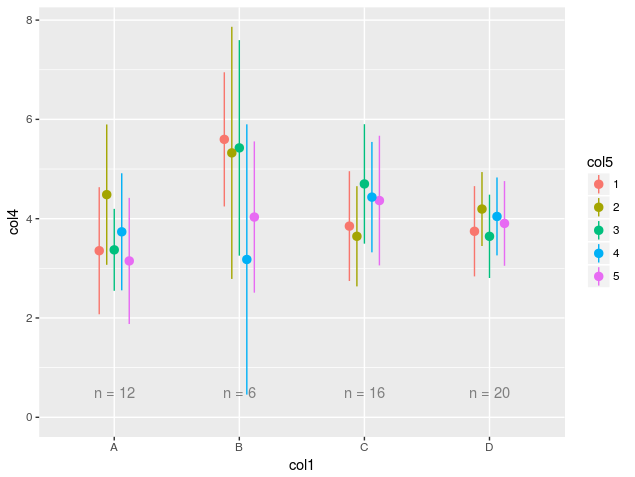
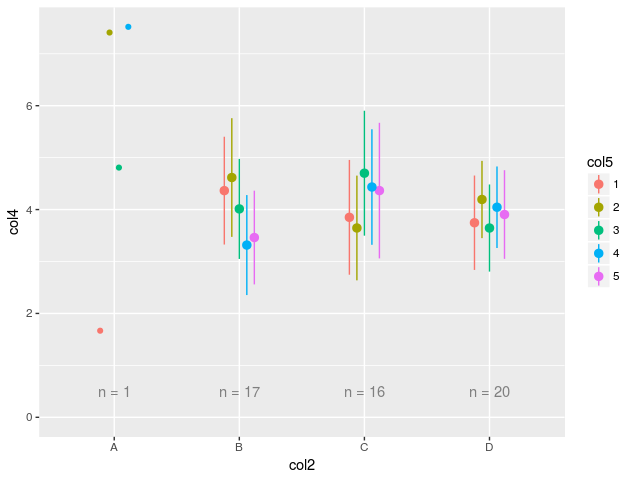
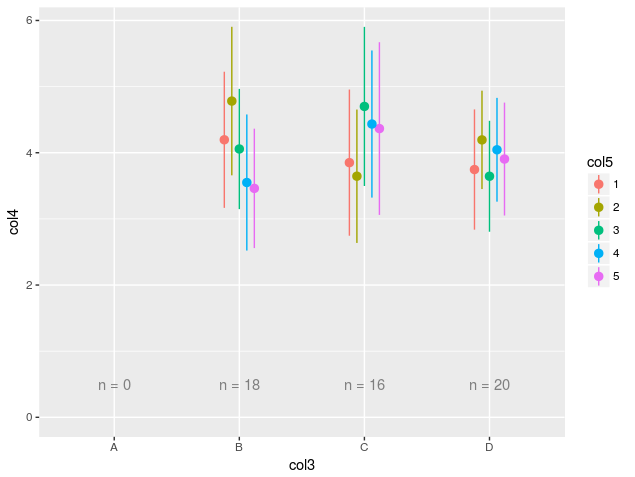
在@Nettle的请求下,我修改了代码以使用更多的tidyverse,特别是使用标准评估来循环列列表,而不是使用以前的基本table方法。我认为代码的功能应该是相同的。主要的优点是删除中间变量,尽管可以说这些变量可以提高可读性。
getPlotList <- function(param.list, data=db, y, color){
param.list %>% sapply(function(var){
ggplot(data=data, aes_string(x=var, y=y, color=color))+
stat_summary(fun.data = mean_cl_normal, position = position_dodge(0.3), na.rm = TRUE) +
stat_summary(fun.y = mean, geom = "point", position = position_dodge(0.3), na.rm = TRUE) +
ylim(0, NA) +
geom_text(aes_string(x = var, y = "y", label = "label", color = NA)
, data %>%
count(!!as.name(var), !!as.name(color)) %>%
group_by(!!as.name(var)) %>%
summarise(
label = paste("n =", paste(unique(n), collapse = ";"))
) %>%
mutate(y = 0.5)
, show.legend = FALSE)
}, simplify = FALSE, USE.NAMES = TRUE)
}https://stackoverflow.com/questions/48191554
复制相似问题
腾讯云开发者
