
如何处理H2O算法中的倾斜响应
在我的问题中,dataset响应变量非常偏左。我试着将模型与h2o.randomForest()和h2o.gbm()相匹配,如下所示。我可以给曲调min_split_improvement和min_rows,以避免过度适应这两种情况。但是有了这些模型,我发现尾部观测有很高的误差。我尝试过使用weights_column对尾部观测数据进行过采样,并对其他观测数据进行过采样,但这并没有帮助。
h2o.model <- h2o.gbm(x = predictors, y = response, training_frame = train,valid = valid, seed = 1,
ntrees =150, max_depth = 10, min_rows = 2, model_id = "GBM_DD", balance_classes = T, nbins = 20, stopping_metric = "MSE",
stopping_rounds = 10, min_split_improvement = 0.0005)
h2o.model <- h2o.randomForest(x = predictors, y = response, training_frame = train,valid = valid, seed = 1,ntrees =150, max_depth = 10, min_rows = 2, model_id = "DRF_DD", balance_classes = T, nbins = 20, stopping_metric = "MSE",
stopping_rounds = 10, min_split_improvement = 0.0005)为了获得更好的性能,我尝试了h2o包的h2o函数。然而,我认为这是非常过份的。我不知道在h2o.automl()中有任何参数来控制过拟合。
有人知道如何避免过度使用h2o.automl()**?** 吗?
编辑
给出了log变换响应的分布情况。根据Erin的建议
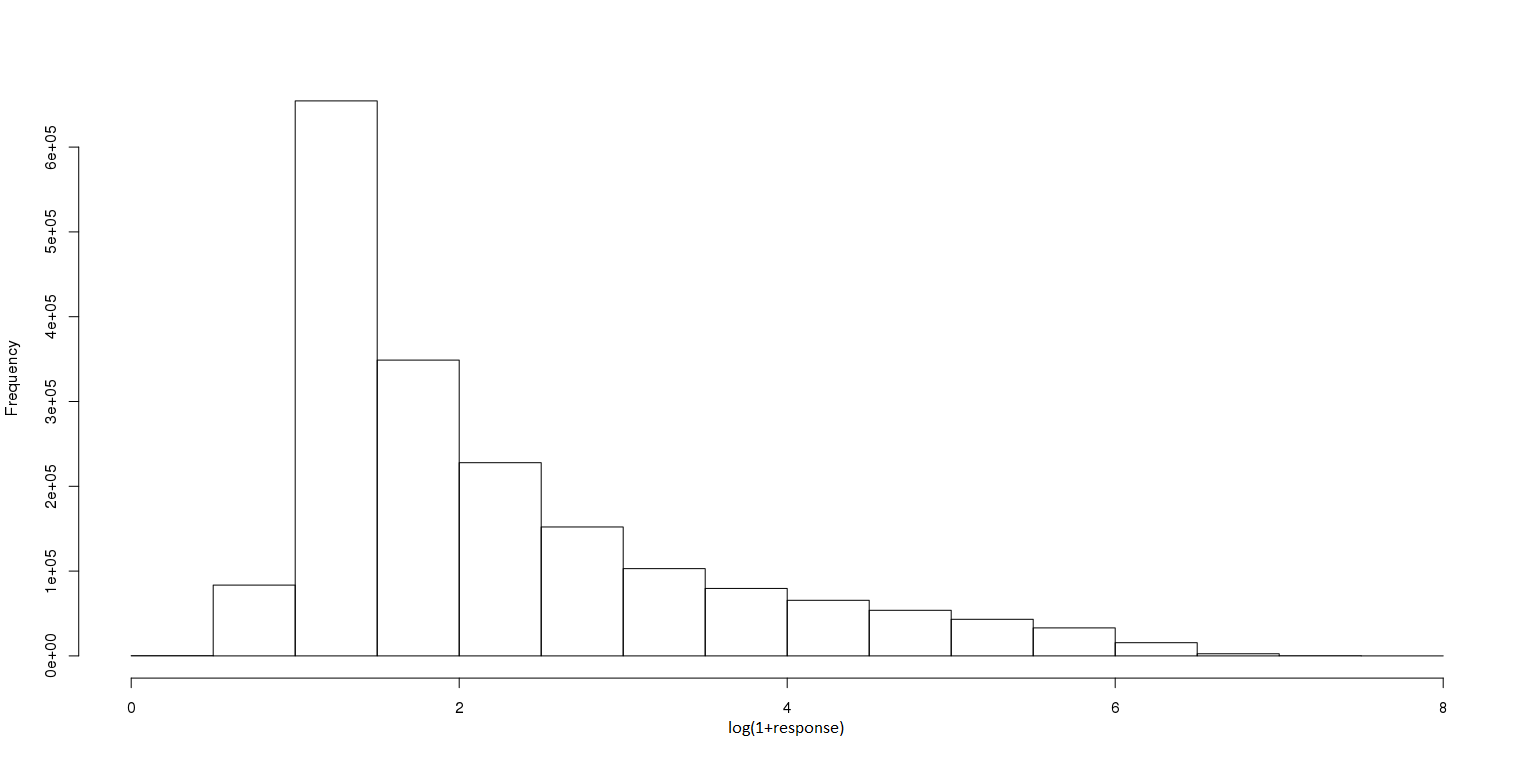
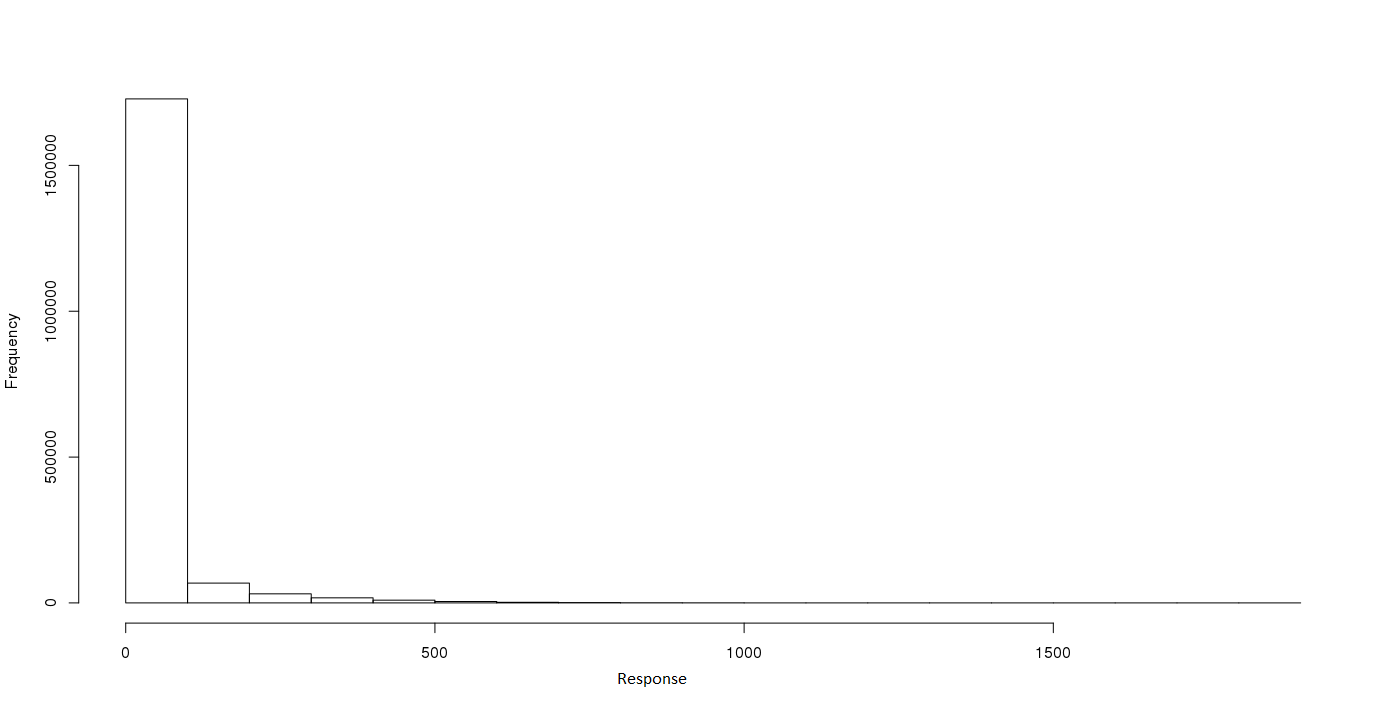
EDIT2:原始反应的分布。
回答 2
Stack Overflow用户
发布于 2018-01-18 21:32:18
H2O AutoML在底层使用H2O标志(例如RF、GBM),所以如果你不能在那里得到好的模型,那么使用AutoML就会遇到同样的问题。我不确定我是否会认为这太合适了--更重要的是,你的模型在预测异常值方面做得不好。
我的建议是记录您的响应变量--当您有一个倾斜的响应时,这是一件有用的事情。将来,H2O AutoML将尝试自动检测一个倾斜的响应并接受日志,但这不是当前版本(H2O 3.16.*)的一个特性。
如果您不熟悉这个过程,这里有一些更详细的内容。首先,创建一个新列,例如log_response,如下所示,并将其用作培训时的响应(在RF、GBM或AutoML中):
train[,"log_response"] <- h2o.log(train[,response])注意:如果您的响应中有零,则应该使用h2o.log1p()。确保不要在预测器中包含原始响应。在您的示例中,您不需要更改任何内容,因为您已经使用predictors向量显式地指定了预测器。
请记住,当您记录响应时,您的预测和模型度量将在日志规模上。因此,如果您需要将您的预测转换回正常的比例,如:
model <- h2o.randomForest(x = predictors, y = "log_response",
training_frame = train, valid = valid)
log_pred <- h2o.predict(model, test)
pred <- h2o.exp(log_pred)这给出了预测,但如果您也希望看到度量,则必须使用新的preds来计算使用h2o.make_metrics()函数的度量,而不是从模型中提取度量。
perf <- h2o.make_metrics(predicted = pred, actual = test[,response])
h2o.mse(perf)您可以像我前面展示的那样使用RF、GBM或AutoML (这应该比单个RF或GBM提供更好的性能)来尝试。
希望这有助于提高您的模型的性能!
Stack Overflow用户
发布于 2019-01-09 03:09:38
当目标变量被倾斜时,mse并不是一个很好的度量。我会尝试更改损失函数,因为gbm试图将模型拟合成损失函数的梯度,并且您希望确保使用的分布是正确的。如果你有一个尖峰的零和右倾斜的积极目标,也许推特将是一个更好的选择。
https://stackoverflow.com/questions/48330026
复制相似问题
腾讯云开发者
