
与GPU的google col堕胎` `ResourceExhaustedError`‘
我正在尝试使用Vgg16微调一个colaboratory模型,但是我在使用GPU进行训练时遇到了这个错误。
OOM when allocating tensor of shape [7,7,512,4096]
INFO:tensorflow:Error reported to Coordinator: <class 'tensorflow.python.framework.errors_impl.ResourceExhaustedError'>, OOM when allocating tensor of shape [7,7,512,4096] and type float
[[Node: vgg_16/fc6/weights/Momentum/Initializer/zeros = Const[_class=["loc:@vgg_16/fc6/weights"], dtype=DT_FLOAT, value=Tensor<type: float shape: [7,7,512,4096] values: [[[0 0 0]]]...>, _device="/job:localhost/replica:0/task:0/device:GPU:0"]()]]
Caused by op 'vgg_16/fc6/weights/Momentum/Initializer/zeros', defined at:还有我的vm会话的输出:
--- colab vm info ---
python v=3.6.3
tensorflow v=1.4.1
tf device=/device:GPU:0
model name : Intel(R) Xeon(R) CPU @ 2.20GHz
model name : Intel(R) Xeon(R) CPU @ 2.20GHz
MemTotal: 13341960 kB
MemFree: 1541740 kB
MemAvailable: 10035212 kB我的tfrecord仅为118256x256 JPG和file size <2MB
有解决办法吗?当我使用CPU时,它可以工作,而不是GPU。
回答 4
Stack Overflow用户
发布于 2018-09-06 23:39:21
看到少量的空闲GPU内存,几乎总是表明您已经创建了一个没有TensorFlow选项的allow_growth = True会话。请参阅:growth
如果不设置此选项,默认情况下,在创建会话时,TensorFlow将保留几乎所有GPU内存。
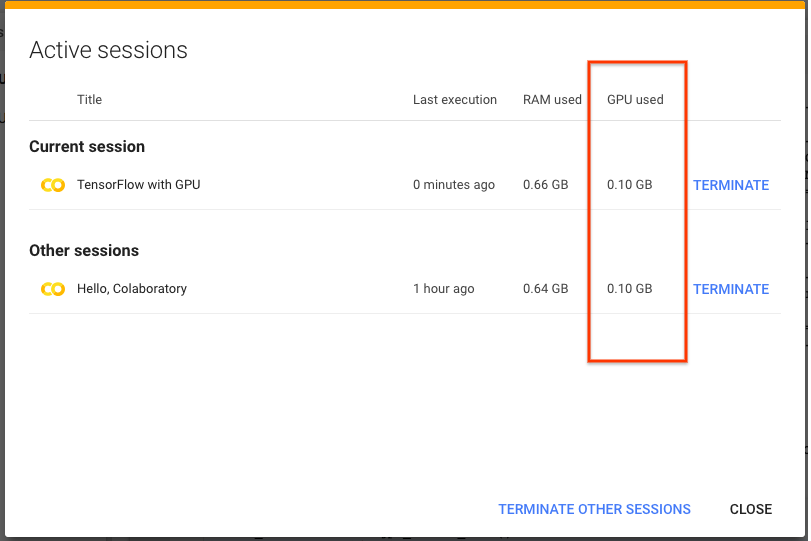
好消息:截至本周,Colab现在默认设置此选项,因此,在Colab上使用多本笔记本时,您应该会看到增长要低得多。此外,您还可以通过从运行时菜单中选择“管理会话”来检查每个笔记本的GPU内存使用情况。
一旦被选中,您将看到一个对话框,其中列出了所有笔记本和GPU内存。要释放内存,您也可以从此对话框中终止运行时。
Stack Overflow用户
发布于 2018-07-25 08:08:22
我遇到了同样的问题,我发现我的问题是由下面的代码引起的:
from tensorflow.python.framework.test_util import is_gpu_available as tf
if tf()==True:
device='/gpu:0'
else:
device='/cpu:0'我使用下面的代码来检查GPU内存使用状态,在运行上面的代码之前,它的使用率是0%,在运行后它变成了95%。
# memory footprint support libraries/code
!ln -sf /opt/bin/nvidia-smi /usr/bin/nvidia-smi
!pip install gputil
!pip install psutil
!pip install humanize
import psutil
import humanize
import os
import GPUtil as GPU
GPUs = GPU.getGPUs()
# XXX: only one GPU on Colab and isn't guaranteed
gpu = GPUs[0]
def printm():
process = psutil.Process(os.getpid())
print("Gen RAM Free: " + humanize.naturalsize( psutil.virtual_memory().available ), " I Proc size: " + humanize.naturalsize( process.memory_info().rss))
print('GPU RAM Free: {0:.0f}MB | Used: {1:.0f}MB | Util {2:3.0f}% | Total {3:.0f}MB'.format(gpu.memoryFree, gpu.memoryUsed, gpu.memoryUtil*100, gpu.memoryTotal))
printm()在此之前:
无内存:12.7GB I程序大小: 139.1 MB GPU RAM空闲:11438 1MB使用:1MB\ Util 0% =11439 1MB
之后:
Gen空闲:12.0GB I Proc大小:1.0GB GPU内存空闲:564 95使用:10875 95\ Util 95%
不知怎么的,is_gpu_available()管理下使用了大部分GPU内存,而没有在之后释放它们,因此,我使用下面的代码来检测gpu状态,解决了问题。
!ln -sf /opt/bin/nvidia-smi /usr/bin/nvidia-smi
!pip install gputil
try:
import GPUtil as GPU
GPUs = GPU.getGPUs()
device='/gpu:0'
except:
device='/cpu:0'Stack Overflow用户
发布于 2018-01-30 20:50:03
我未能复制最初报告的错误,但如果这是由于GPU内存不足(而不是主内存)不足造成的,这可能会有所帮助:
# See https://www.tensorflow.org/tutorials/using_gpu#allowing_gpu_memory_growth
config = tf.ConfigProto()
config.gpu_options.allow_growth = True然后将session_config=config传递给例如slim.learning.train() (或您最终使用的会话ctor )。
https://stackoverflow.com/questions/48494853
复制相似问题
腾讯云开发者
