
在R中将图像转换为黑白图像识别
在R中将图像转换为黑白图像识别
提问于 2018-01-31 22:34:26
我试图获得一些自动文本识别的经验,我正在使用包tesseract对一些图像执行ocr (即我拍摄的一些屏幕截图)。
为了提高程序对图像中价格的识别性能,通过改变亮度和饱和度参数,利用magick软件包,在图像上实现了一些预处理。
但是,我认为通过转换为黑白图像可以进一步提高性能。
如何在R中有效地实现这一点?
原始图像
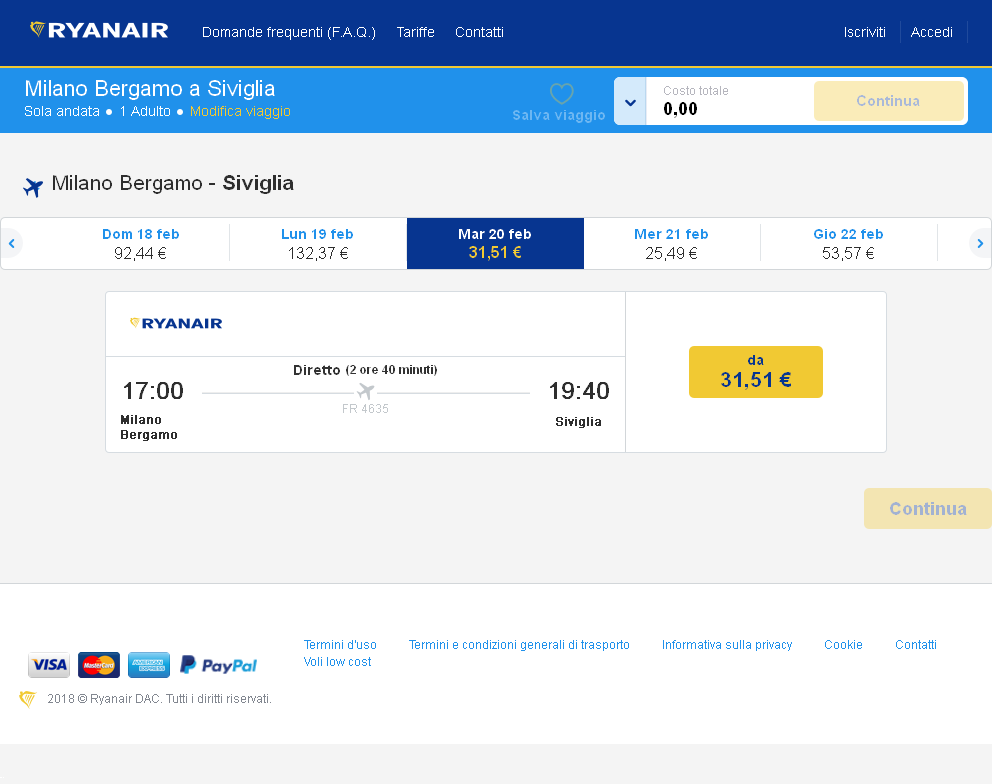
后预处理
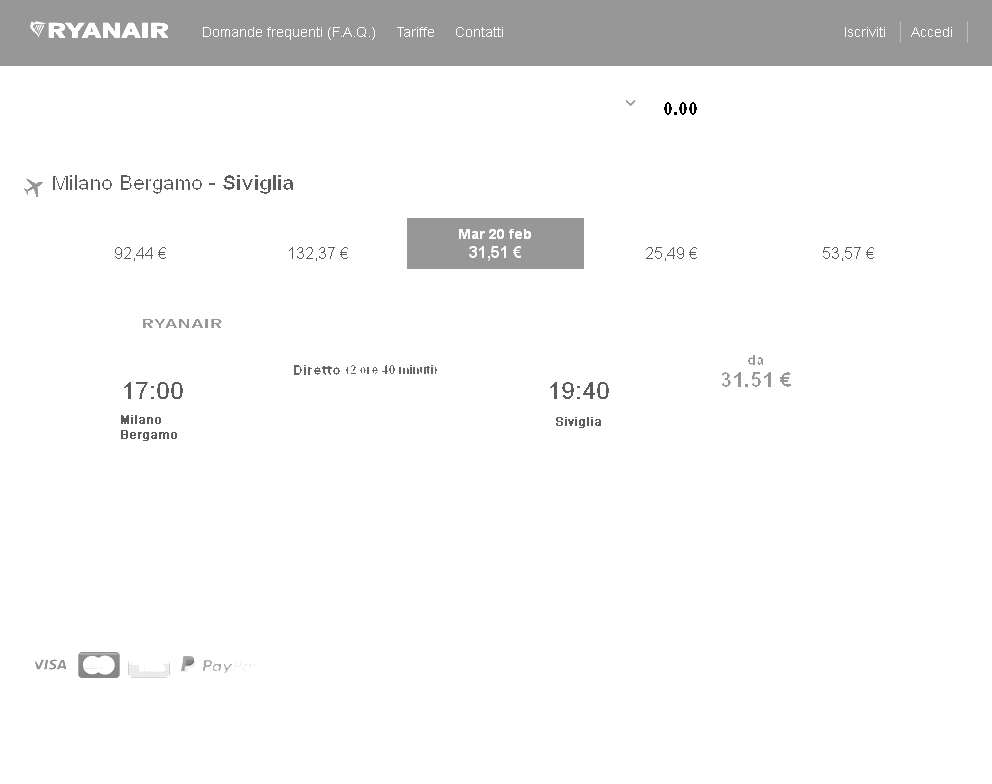
回答 2
Stack Overflow用户
回答已采纳
发布于 2018-01-31 23:22:54
您可以使用magick::image_quantize转换颜色空间
library(magick)
#> Linking to ImageMagick 6.9.9.25
#> Enabled features: cairo, fontconfig, freetype, fftw, lcms, pango, rsvg, webp
#> Disabled features: ghostscript, x11
i <- image_read('https://i.stack.imgur.com/nn9k0.png')
i
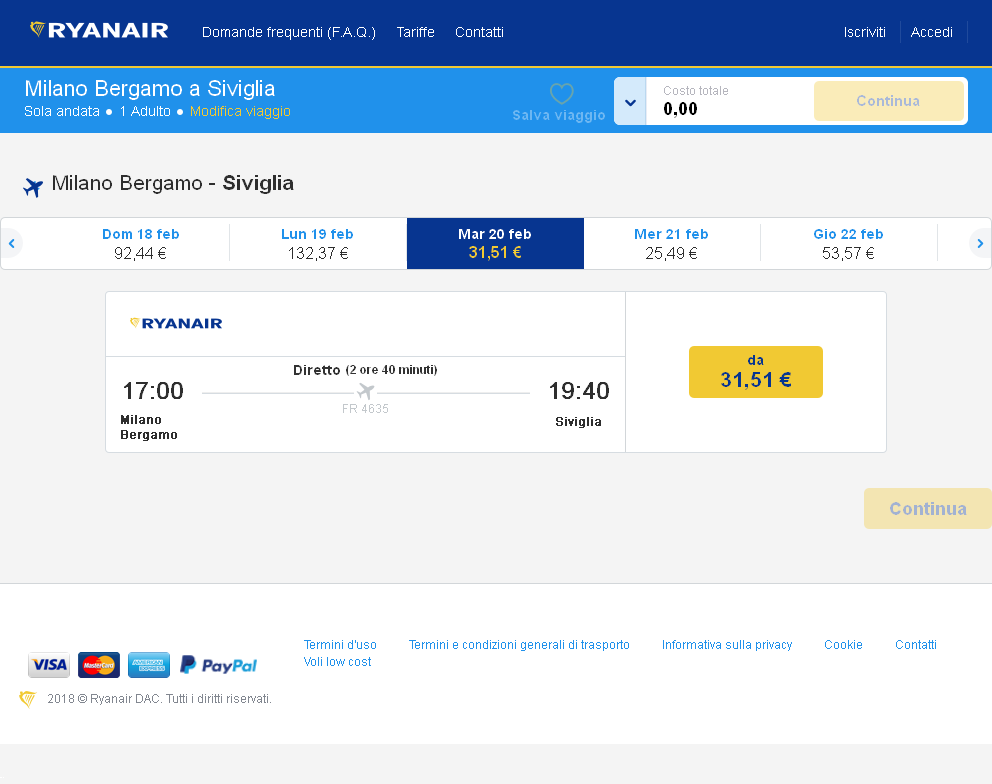
i %>% image_quantize(colorspace = 'gray')

根据所需的图像结构,还可以使用image_convert进行相同的操作:
i %>% image_convert(colorspace = 'gray')
# or
i %>% image_convert(type = 'Grayscale')或者转换成真正的黑白(不是灰度),
i %>% image_convert(type = 'Bilevel')

在这种情况下,它返回带有盐分和胡椒噪声的图像,这可能有用,也可能没有用。
但是,请注意,虽然这可能是OCR的良好实践,但通过get抓取获取这些数据要简单得多,例如,如果允许使用红背心 (想必同样的问题也适用于获取这些图像)。更好的是,如果它包含您需要的信息,则使用适当的RyanAir API。
Stack Overflow用户
发布于 2018-01-31 23:31:13
在ImageMagick命令行中,您可以简单地以一定的百分比阈值。我在这里用了50%,但根据需要调整。
convert image.png -threshold 50% result.png
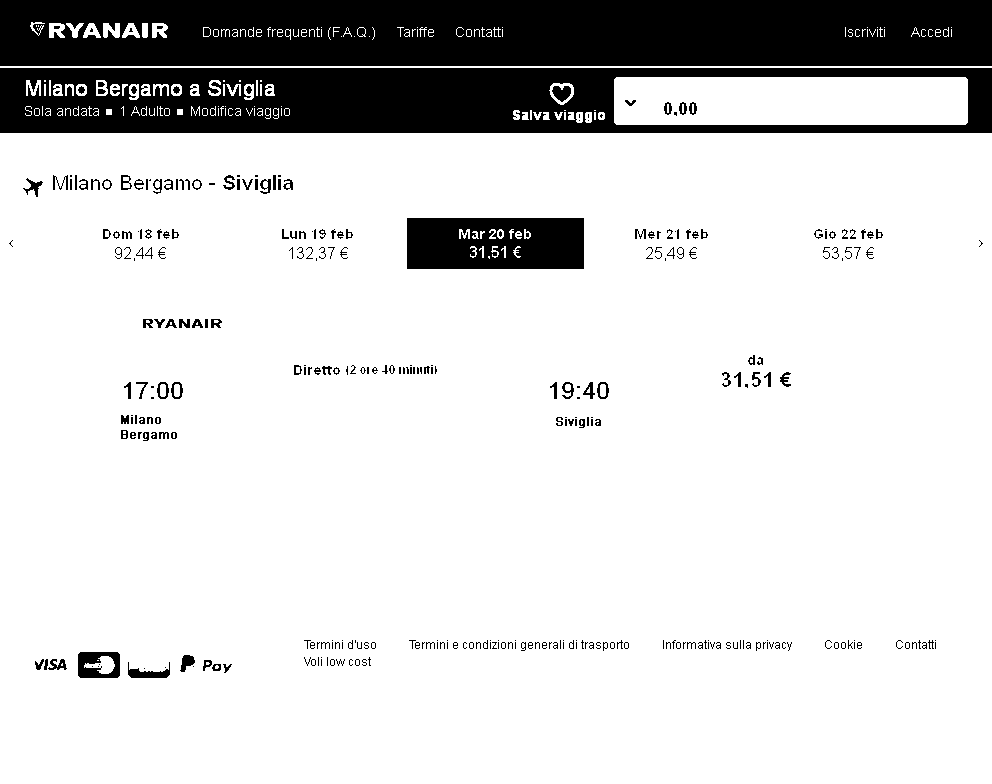
在Imagick中,命令是Imagick::阈值图像。见http://php.net/manual/en/imagick.thresholdimage.php。对不起,我不知道您使用的是哪个"Magick“包。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/48552565
复制相关文章
相似问题
腾讯云开发者
