
在比较两列的基础上,从第二个DataFrame中添加列
简单地说,我试图将latitude和longitude列从df1添加到一个名为df2的较小的DataFrame中,方法是比较它们的air_id和hpg_id列的值:

将latitude和longitude添加到df2中的技巧取决于如何与df1进行比较,这可能是3种情况之一:
- 当
df2.air_id和df1.air_hd之间有匹配时; - 当
df2.hpg_id和df1.hpg_hd之间有匹配时; - 当两者之间有匹配时:
[df2.air_id, df2.hpg_id]和[df1.air_hd, df1.hpg_id];
考虑到这一点,预期结果应是:
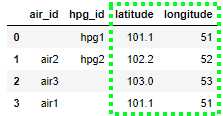
请注意,如何将来自df1的df1列排除在结果DataFrame之外。
下面是设置DataFrames的代码:
data = { 'air_id' : [ 'air1', '', 'air3', 'air4', 'air2', 'air1' ],
'hpg_id' : [ 'hpg1', 'hpg2', '', 'hpg4', '', '' ],
'latitude' : [ 101.1, 102.2, 103, 104, 102, 101.1, ],
'longitude' : [ 51, 52, 53, 54, 52, 51, ],
'ignore_me' : [ 91, 92, 93, 94, 95, 96 ] }
df1 = pd.DataFrame(data)
display(df1)
data2 = { 'air_id' : [ '', 'air2', 'air3', 'air1' ],
'hpg_id' : [ 'hpg1', 'hpg2', '', '' ] }
df2 = pd.DataFrame(data2)
display(df2)不幸的是,我未能将merge()用于此任务。我当前的结果是一个DataFrame,它包含来自df1的所有列,其中大部分都填充了NaNs。
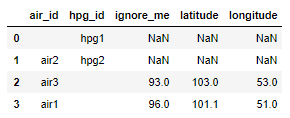
如何使用上述规则从df1复制这些特定列?
回答 3
Stack Overflow用户
发布于 2018-03-16 22:20:08
这里有一种方法可以完成你想要做的事情。
首先使用merge()两次。首先在air_id上,然后在hpg_id上。对于这两种情况,忽略键是空字符串时的琐碎情况。
result = df2\
.merge(
df1[df1['air_id']!=''].drop(['hpg_id'], axis=1), on=['air_id'], how='left'
)\
.merge(
df1[df1['hpg_id']!=''].drop(['air_id'], axis=1), on=['hpg_id'], how='left'
)
print(result)
# air_id hpg_id ignore_me_x latitude_x longitude_x ignore_me_y \
#0 hpg1 NaN NaN NaN 91
#1 air2 hpg2 92.0 102.0 52.0 92
#2 hpg3 NaN NaN NaN 93
#
# latitude_y longitude_y
#0 101 51
#1 102 52
#2 103 53 但是,这会为所需的列创建重复项。(我在每次调用中删除另一个联接键以合并,以避免这些调用的列名重复。)
通过采用this post上描述的方法之一,我们可以合并这些值。
cols = ['latitude', 'longitude']
colsx = list(map(lambda c: c+"_x", cols)) # list needed for python3
colsy = list(map(lambda c: c+"_y", cols)) # list needed for python3
result[cols] = pd.DataFrame(
np.where(result[colsx].isnull() == True, result[colsy], result[colsx])
)
result = result[['air_id', 'hpg_id'] + cols]
print(result)
# air_id hpg_id latitude longitude
#0 hpg1 101.0 51.0
#1 air2 hpg2 102.0 52.0
#2 air3 103.0 53.0更新
在合并生成重复条目的情况下,可以使用pandas.DataFrame.drop_duplicates()。
result = result.drop_duplicates()Stack Overflow用户
发布于 2018-03-16 23:26:18
用布景和Numpy广播来处理东西的匹配.洒满仙尘
ids = ['air_id', 'hpg_id']
cols = ['latitude', 'longitude']
def true(s): return s.astype(bool)
s2 = df2.stack().loc[true].groupby(level=0).apply(set)
s1 = df1[ids].stack().loc[true].groupby(level=0).apply(set)
i, j = np.where((s1.values & s2.values[:, None]).astype(bool))
a = np.zeros((len(df2), 2), int)
a[i, :] = df1[cols].values[j]
df2.join(pd.DataFrame(a, df2.index, cols))
air_id hpg_id latitude longitude
0 hpg1 101 51
1 air2 hpg2 102 52
2 hpg3 103 53详细信息
s2看起来像这样
0 {hpg1}
1 {air2, hpg2}
2 {hpg3}
dtype: object和s1
0 {air1, hpg1}
1 {hpg2}
2 {hpg3}
3 {air4, hpg4}
4 {air2}
dtype: object关键是,我们想要找到该行中的任何内容是否与其他数据帧中的任何内容相匹配。现在我可以使用广播和&了
s1.values & s2.values[:, None]
array([[{'hpg1'}, set(), set(), set(), set()],
[set(), {'hpg2'}, set(), set(), {'air2'}],
[set(), set(), {'hpg3'}, set(), set()]], dtype=object)但是,空集在布尔上下文中计算为False,因此
(s1.values & s2.values[:, None]).astype(bool)
array([[ True, False, False, False, False],
[False, True, False, False, True],
[False, False, True, False, False]], dtype=bool)现在我可以使用np.where向我展示这些True的位置了。
i, j = np.where((s1.values & s2.values[:, None]).astype(bool))
print(i, j)
[0 1 1 2] [0 1 4 2]这些分别是来自df2和df1的行。但是我不需要两行1,所以我创建了一个具有适当大小的空数组,并期望覆盖行1。我用来自df1的lats和lons填充这些值
a = np.zeros((len(df2), 2), int)
a[i, :] = df1[cols].values[j]
a
array([[101, 51],
[102, 52],
[103, 53]])然后,我将其包装在一个pd.DataFrame中,并加入上面的内容。
Stack Overflow用户
发布于 2018-03-16 22:49:53
这是一种没有合并的手动方式。它不是有效的,但是如果它对您的用例执行得足够好,那么它可能是可管理的。
df1['lat_long'] = list(zip(df1['latitude'], df1['longitude']))
air = df1[df1['air_id'] != ''].set_index('air_id')['lat_long']
hpg = df1[df1['hpg_id'] != ''].set_index('hpg_id')['lat_long']
def mapper(row):
myair, myhpg = row['air_id'], row['hpg_id']
if (myair != '') and (myair in air):
return air.get(myair)
elif (myhpg != '') and (myhpg in hpg):
return hpg.get(myhpg)
elif (myair != '') and (myair in hpg):
return hpg.get(myair)
elif (myhpg != '') and (myhpg in air):
return air.get(myhpg)
else:
return (None, None)
df2['lat_long'] = df2.apply(mapper, axis=1)
df2[['latitude', 'longitude']] = df2['lat_long'].apply(pd.Series)
df2 = df2.drop('lat_long', 1)
# air_id hpg_id latitude longitude
# 0 hpg1 101 51
# 1 air2 hpg2 102 52
# 2 hpg3 103 53https://stackoverflow.com/questions/49329997
复制相似问题
腾讯云开发者
