
std() Pandas发行
std() Pandas发行
提问于 2018-03-22 04:14:19
,这会是个bug吗?当我对groupby对象使用describe()或std()时,我得到了不同的答案--
import pandas as pd
import numpy as np
import random as rnd
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar',
...: 'foo', 'bar', 'foo', 'foo'],
...: 'B' : ['one', 'one', 'two', 'three',
...: 'two', 'two', 'one', 'three'],
...: 'C' : 1*(np.random.randn(8)>0.5),
...: 'D' : np.random.randn(8)})
df.head()
df[['C','D']].groupby(['C'],as_index=False).describe()
# this line gives me the standard deviation of 'C' to be 0,0. Within each group value of C is constant, so that makes sense.
df[['C','D']].groupby(['C'],as_index=False).std()
# This line gives me the standard deviation of 'C' to be 0,1. I think this is wrong回答 3
Stack Overflow用户
回答已采纳
发布于 2018-03-22 04:23:55
这不足为奇。在第二种情况下,您只计算列D的D。
多么?这正是groupby的工作方式。你
C和D上的切片groupbyonC- 调用
GroupBy.std
在步骤3中,您没有指定任何列,因此假定std是在不是石斑鱼的列上计算的。又名,D列。
至于你为什么看到C和0, 1..。这是因为您指定了as_index=False,因此插入了C列,其中包含来自原始dataFrame的值。在本例中是0, 1。
运行这个,它就会变得清晰。
df[['C','D']].groupby(['C']).std()
D
C
0 0.998201
1 NaN当您指定as_index=False时,您看到的索引将作为一个列插入。把这个和,
df[['C','D']].groupby(['C'])[['C', 'D']].std()
C D
C
0 0.0 0.998201
1 NaN NaN这正是describe给出的内容,也是您要寻找的内容。
Stack Overflow用户
发布于 2018-04-12 18:07:38
我的朋友mukherjees和我用这个做了更多的试验,并认为std()确实有问题。您可以在下面的链接中看到"std()与.apply(np.std,ddof=1)“的显示方式。在注意到之后,我们还发现了以下相关的bug报告:
Stack Overflow用户
发布于 2018-03-22 04:27:22
即使使用std(),您也将在每个组中得到C的零标准差。我只是在您的代码中添加了一个种子,以使其可复制。我不知道有什么问题-
import pandas as pd
import numpy as np
import random as rnd
np.random.seed=1987
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar',
'foo', 'bar', 'foo', 'foo'],
'B' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'C' : 1*(np.random.randn(8)>0.5),
'D' : np.random.randn(8)})
df
df[['C','D']].groupby(['C'],as_index=False).describe()

df[['C','D']].groupby(['C'],as_index=False).std()
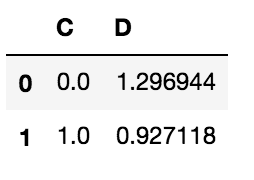
为了进一步深入,如果您查看从DataFrame.describe继承的的源代码,
def describe_numeric_1d(series):
stat_index = (['count', 'mean', 'std', 'min'] +
formatted_percentiles + ['max'])
d = ([series.count(), series.mean(), series.std(), series.min()] +
[series.quantile(x) for x in percentiles] + [series.max()])
return pd.Series(d, index=stat_index, name=series.name)上面的代码只显示了std()的结果
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/49420444
复制相关文章
相似问题
腾讯云开发者
