
如何计算事件的总持续时间?
我收集了一个数据文件,它对成员通信(Discourse Code)和构造模型(Modeling Code)的组问题解决会话中事件的持续时间进行建模。发生的每分钟都在Time_Processed列中捕获。从技术上讲,这些事件同时发生。我想知道学生们构建每一种模型的时间,即该模型的总持续时间或该模型更改前所需的时间。
我有以下数据集:
看起来是这样的:
`Modeling Code` `Discourse Code` Time_Processed
<fct> <fct> <dbl>
1 OFF OFF 10.0
2 MA Q 11.0
3 MA AG 16.0
4 V S 18.0
5 V Q 20.0
6 MA C 21.0
7 MA C 23.0
8 MA C 25.0
9 V J 26.0
10 P S 28.0
# My explicit dataframe.
df <- structure(list(`Modeling Code` = structure(c(3L, 2L, 2L, 6L,
6L, 2L, 2L, 2L, 6L, 4L), .Label = c("A", "MA", "OFF", "P", "SM",
"V"), class = "factor"), `Discourse Code` = structure(c(7L, 8L,
1L, 9L, 8L, 2L, 2L, 2L, 6L, 9L), .Label = c("AG", "C", "D", "DA",
"G", "J", "OFF", "Q", "S"), class = "factor"), Time_Processed = c(10,
11, 16, 18, 20, 21, 23, 25, 26, 28)), row.names = c(NA, -10L), .Names = c("Modeling Code",
"Discourse Code", "Time_Processed"), class = c("tbl_df", "tbl",
"data.frame"))对于这个数据,我可以找到学生们在逻辑上构建每一种模型的频率。
关于Modeling Code和Time_Processed列,
在10分钟,他们使用OFF模型方法,然后在11分钟,他们改变模型,所以关闭模型的持续时间是(11-10)分钟=1分钟。没有其他" OFF“方法出现,因此持续时间OFF=1分钟。
同样,对于建模代码方法"MA",模型被使用从11分钟到16分钟(持续时间=5分钟),然后从16分钟到18分钟,然后模型变为V(持续时间=2分钟),然后模型在21分钟再次使用,26分钟结束(持续时间=5分钟)。因此,"MA“的总持续时间为(5 +2+ 5)分钟= 12分钟。
同样,建模代码方法"V“的持续时间从18分钟开始,结束于21分钟(持续时间=3分钟),恢复到26分钟,结束于28分钟(持续时间= 2)。的总持续时间为3+2=5 minutes。
然后,建模代码P的持续时间从28分钟开始,没有连续性,因此P的总持续时间为0分钟。
因此,建模代码的总持续时间(分钟)表如下:
Modeling Code Total_Duration
OFF 1
MA 12
V 5
P 0 这个模型的条形图如下所示:
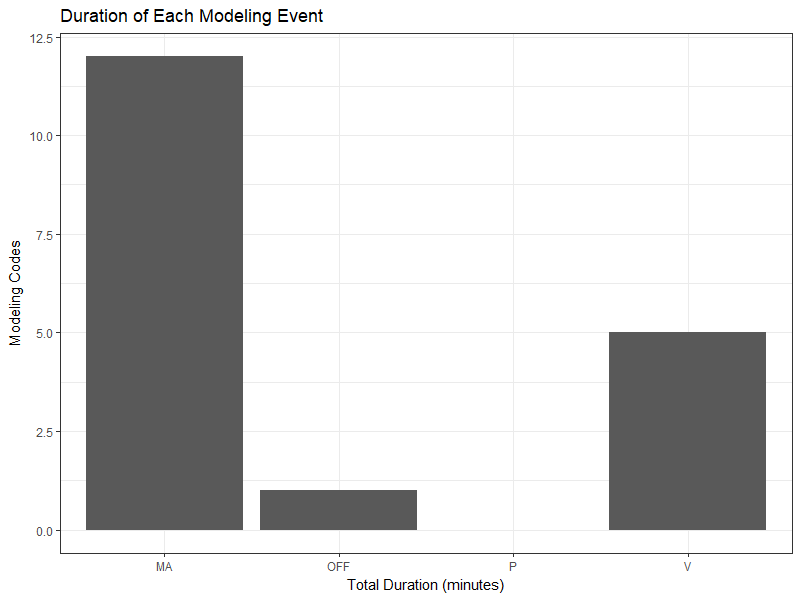
如何构建这些建模方法的总持续时间?
知道组合的持续时间也很好,在这个小子集中唯一可见的组合恰好是建模代码"MA“和语篇代码"C”,这种组合发生时间为26-21=5分钟。
谢谢。
回答 1
Stack Overflow用户
发布于 2018-03-23 03:53:21
更新解决方案
df %>%
mutate(dur = lead(Time_Processed) - Time_Processed) %>%
replace_na(list(dur = 0)) %>%
group_by(`Modeling Code`) %>%
summarise(tot_time = sum(dur))(^感谢Nick DiQuattro)
以前的解决方案
这里有一个创建新变量mcode_grp的解决方案,它跟踪同一个Modeling Code的离散分组。它并不特别漂亮--它需要遍历df中的每一行--但它可以工作。
首先,重命名列以便于参考:
df <- df %>%
rename(m_code = `Modeling Code`,
d_code = `Discourse Code`)我们将使用一些额外的变量更新df。
lead_time_proc为我们提供了df中下一行的Time_Processed值,在计算每个m_code批处理的总时间量时将需要该值。- 用于在迭代中跟踪行号的
row_n mcode_grp是每个m_code批处理的唯一标签。
df <- df %>%
mutate(lead_time_proc = lead(Time_Processed),
row_n = row_number(),
mcode_grp = "") 接下来,我们需要一种方法来跟踪我们何时已经到达一个给定的m_code值的新批。一种方法是为每个m_code保留一个计数器,并在到达新批处理时增加计数器。然后,我们可以将该m_code批处理的所有行标记为属于同一时间窗口。
mcode_ct <- df %>%
group_by(m_code) %>%
summarise(ct = 0) %>%
mutate(m_code = as.character(m_code))这是最丑的部分。我们遍历df中的每一行,并检查是否达到了新的m_code。如果是这样,我们将相应地更新,并为每一行注册一个mcode_grp值。
mc <- ""
for (i in 1:nrow(df)) {
current_mc <- df$m_code[i]
if (current_mc != mc) {
mc <- current_mc
mcode_ct <- mcode_ct %>% mutate(ct = ifelse(m_code == mc, ct + 1, ct))
current_grp <- mcode_ct %>% filter(m_code == mc) %>% select(ct) %>% pull()
}
df <- df %>% mutate(mcode_grp = ifelse(row_n == i, current_grp, mcode_grp))
}最后,group_by m_code和mcode_grp计算每个批处理的持续时间,然后对m_code值进行求和。
df %>%
group_by(m_code, mcode_grp) %>%
summarise(start_time = min(Time_Processed),
end_time = max(lead_time_proc)) %>%
mutate(total_time = end_time - start_time) %>%
group_by(m_code) %>%
summarise(total_time = sum(total_time)) %>%
replace_na(list(total_time=0))输出:
# A tibble: 4 x 2
m_code total_time
<fct> <dbl>
1 MA 12.
2 OFF 1.
3 P 0.
4 V 5.对于任何dplyr/tidyverse专家来说,我很想知道如何在不使用循环和计数器的情况下完成更多的任务!
https://stackoverflow.com/questions/49439340
复制相似问题
腾讯云开发者
