
bizzare编码问题只在查看源时才会造成一个特定网站的胡言乱语。
bizzare编码问题只在查看源时才会造成一个特定网站的胡言乱语。
提问于 2018-03-27 21:11:01
我正在写一个python脚本来获取一些新闻网站的文章,我陷入了一个非常奇怪的编码问题。这是给一位以色列朋友的,所以网站都是希伯来语,我的方法(使用请求和漂亮汤)很有效,直到我来到这个网站,不管我做什么都是胡说八道。网站是马科里松。奇怪的是:当我在浏览器中看到它时,它不是胡言乱语,当我在firefox上使用“two”时,html并不是胡言乱语,当我从浏览器中查看源代码时,它也不是胡说八道(它也不好,它在两块js之间用两行显示整个页面),但是当我使用python时,即使我将html保存到我的计算机中,然后在浏览器中打开保存的文件,它也不是胡说八道。我用任何方式尝试了与希伯来语有关的每一种可能的编码,每一种都给我留下了一套不同的无法理解的符号。这就是它看起来正常的样子:
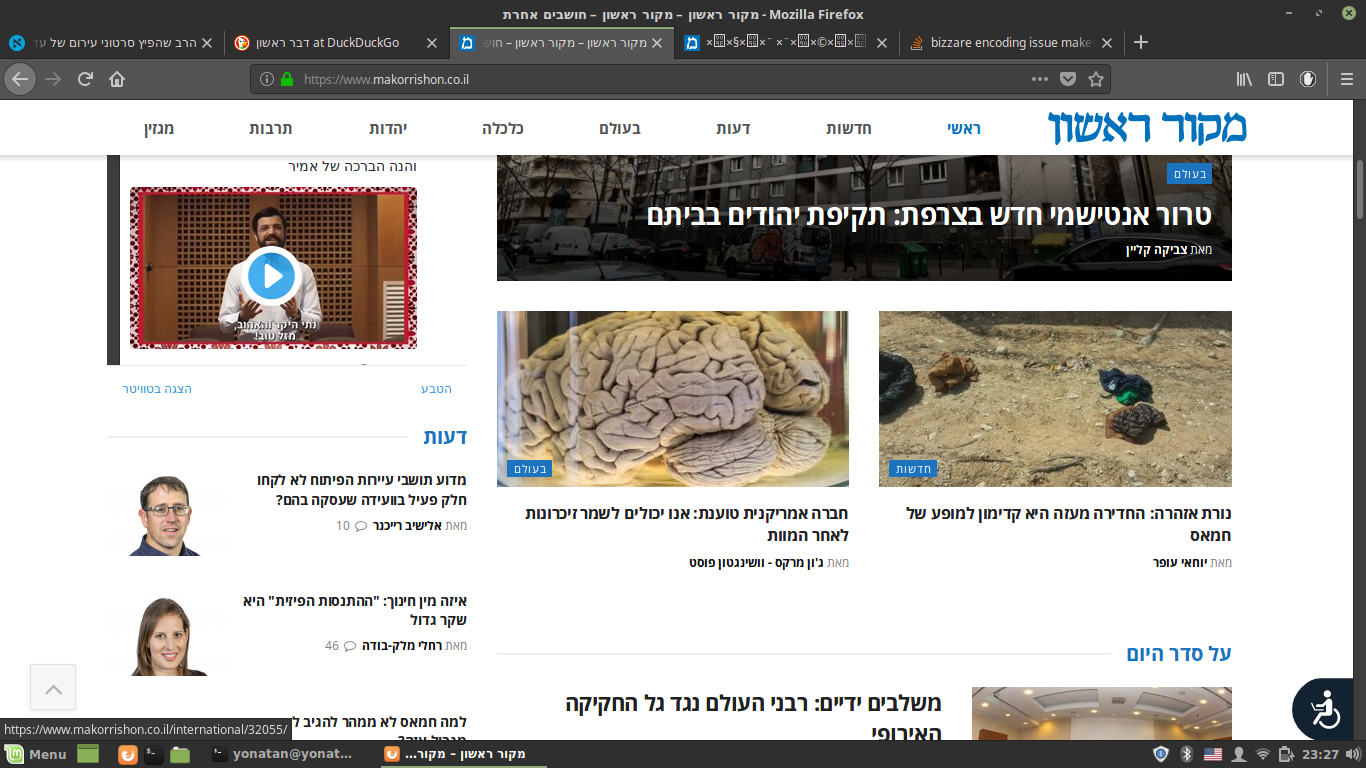
python保存的页面如下所示:

这是我所知道的唯一这样做的网站,我在其他希伯来语网站上使用了同样的工具,结果很好。
用于生成此代码的代码是:
>>> import requests
>>> res = requests.get('https://www.makorrishon.co.il/')
>>> res
<Response [200]>
>>> file = open('makor1.html', 'w')
>>> file.write(res.text)
152957
>>> file.close()这是一台linux笔记本,顺便说一句。
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-03-28 08:25:35
在写入文件之前尝试添加res.encoding = 'utf-8':
if __name__ == '__main__':
import requests
res = requests.get('https://www.makorrishon.co.il/')
res.encoding = 'utf-8'
file = open('makor1.html', 'wb')
file.write(res.text.encode('utf-8'))
file.close()页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/49522462
复制相关文章
相似问题
腾讯云开发者
