
DBSCAN距离函数
我想使用一个聚类算法来找到一个大有向图的聚类,我也想从这个图中去除噪声。因此,我考虑使用DBSCAN方法,因为我看到我们可以给算法一个确定两个不同节点之间距离/相似性的距离函数。
我的问题是,如何定义一个距离函数,当一个节点被隔离时,增加了,两个节点之间的相似性根据跳数结束,减少了。
我没有坐标或节点属性,所以我不能使用这些。我只有图的拓扑。
预期的输出将如下所示:
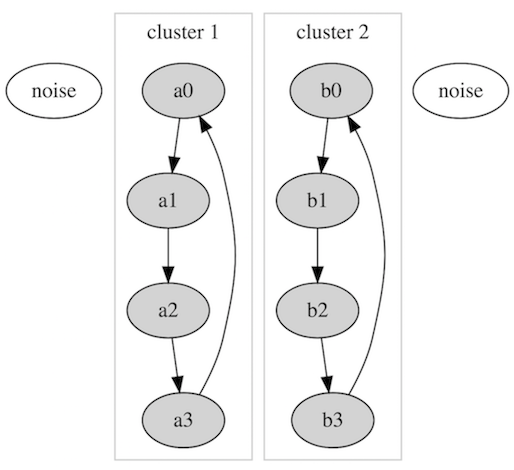
我真的很担心解决方案的复杂性。如何用线性复杂度近似一个聚类.
回答 2
Stack Overflow用户
发布于 2018-04-27 06:08:35
显而易见的有什么问题呢?
距离(a,b) =最短路径的长度,如果没有,则为无穷远。
您可能应该考虑到方向,所以a0到a3 ist 1。
Stack Overflow用户
发布于 2018-04-27 19:35:24
@Anony-Mousse提出的距离度量是一个好的、自然的度量,但我对dbscan的使用表示怀疑。使用拟议的
distance = length of shortest path, or infinity if there is none直接链接的任何两个节点都将位于距离1。如果使用epsilon < 1的dbscan,则所有点都是噪声点。所以你会想要epsilon > 1。从你的例子看,如果距离1甚至有一个点,你想要它们在同一个组件中,所以看起来你想要minNumPts = 2。这会给出两个点通过一个任意长度的路径连接的结果,它们在同一个集群中。在我看来,你所追求的与密度和聚类无关,相反,我认为你想要的是连接的组件。如果两个节点由任意长度的路径连接,则它们位于同一个组件中。可能可以通过dbscan或其他集群方法来找到这一点,但这可能是错误的想法。你有一个图和一个图论问题。你应该使用图论中的方法。
我将用R和igraph来说明。如果你不关心这些,还有其他的工具。
大部分的工作只是简单地设置你的问题。
library(igraph)
to = c("a1", "a2", "a3", "a0", "b1", "b2", "b3", "b0")
from = c("a0", "a1", "a2", "a3", "b0", "b1", "b2", "b3")
EL = data.frame(from, to)
Vert = c("a0", "a1", "a2", "a3", "b0", "b1", "b2", "b3", "c0", "d0")
Vdf = data.frame(Vert)
g = graph_from_data_frame(d = EL, vertices=Vdf)
LO = matrix(c(1.2,1,1,1.2, 2.2,2,2,2.2, 0, 3, 4,3,2,1,4,3,2,1,4,4),
ncol=2)
plot(g, layout=LO)

现在我们可以使用单线线来获取组件所需的一切。
Comp = components(g, mode="weak")
Comp
$membership
a0 a1 a2 a3 b0 b1 b2 b3 c0 d0
1 1 1 1 2 2 2 2 3 4
$csize
[1] 4 4 1 1
$no
[1] 4这就是告诉我们节点的组件成员、每个组件的节点数和组件的数量。因为您希望以dbscan的形式调用单个节点组件"noise“,所以可以看到组件3和4每个都有一个节点。
它们就是噪音。其他的是“真正的”组件。为了展示如何使用这一点,并以一幅漂亮的图片来结束,我将绘制着色组件的图形,并使用浅灰作为“噪声”。
ColorMap = rainbow(Comp$no)
ColorMap[Comp$csize == 1] = "lightgray"
plot(g, layout=LO, vertex.color=ColorMap[Comp$membership])

我鼓励你把你的图问题当作一个图来考虑。
https://stackoverflow.com/questions/50042832
复制相似问题
腾讯云开发者
