
顺序或批参数估计
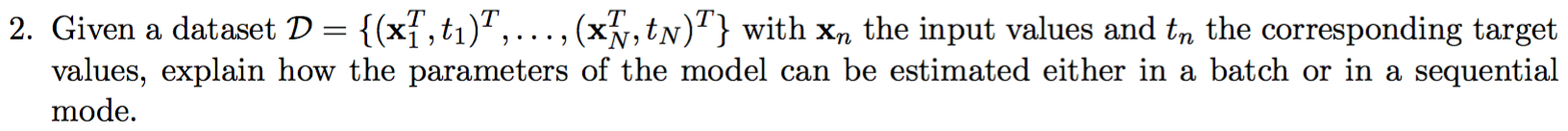
这就是我应该描述的问题。不幸的是,我研究的唯一一种在线性回归中估计参数的方法是经典的梯度下降算法。这是“批处理”模式还是“顺序”模式?他们之间有什么区别?
回答 2
Stack Overflow用户
发布于 2018-06-06 23:18:16
我没想到会在这里找到ML考试的问题!重点是,正如詹姆斯菲利普斯所说的,梯度下降是一种迭代方法,也就是所谓的顺序下降。梯度下降只是一个求函数最小值的迭代优化算法,但是你可以用它来找到‘最佳拟合线’。一个完整的批处理方法是线性最小二乘法,它同时应用所有的方程。您可以找到计算误差平方和的偏导数的所有参数w.r.t。最好的线适合并将其设置为零。当然,正如菲利普斯所说的,这是一个不方便的方法,更多的是一个理论定义。希望是有用的。
Stack Overflow用户
发布于 2019-05-19 16:46:04
来自梁等人。"
批量学习通常是一项耗时的工作,因为它可能涉及到对培训数据的多次迭代。在大多数应用中,这可能需要几分钟到几个小时,并进一步选择学习参数(即学习速率、学习周期数、停止标准和其他预定义的参数)以确保收敛。此外,每当接收到新数据时,批量学习就会将过去的数据与新数据一起使用,并进行再培训,因此花费了大量的时间。在许多工业应用中,在线顺序学习算法优于批处理学习算法,因为当收到新的数据时,顺序学习算法不需要再培训。反向传播(BP)算法及其变体一直是训练具有加性隐藏节点的SLFN的骨干。值得注意的是,BP 基本上是一种批处理学习算法。随机梯度下降BP是序列学习应用的主要变体之一。
基本上,梯度下降是以批处理的方式进行的,但实际上您使用的是迭代方法。
我认为这个问题不是要求你展示两种方法(批处理和顺序)来估计模型的参数,而是解释--无论是在批处理模式还是顺序模式--这样的估计是如何工作的。
例如,如果您试图估计线性回归模型的参数,您可以只描述可能性最大化,这相当于最小化最小二乘误差:
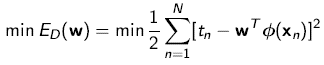
如果要显示顺序模式,可以描述梯度下降算法。
https://stackoverflow.com/questions/50314118
复制相似问题
腾讯云开发者
