
混乱的动物园管理员内存使用情况
我有一个动物园管理员的例子已经跑了一段时间了..。(Java 1.7.0_131,ZK 3.5.1-1),带有-Xmx10G -XX:+UseParallelGC。
最近出现了领导能力的变化,仲裁中大多数情况下的内存使用量从~200 on变为2GB+。我选择了一个jmap转储,我发现有趣的是,有很多byte[]序列化数据(>1GB)没有GC根,但没有被收集。
(这是ByteArrayOutputStream,DataOutputStream,org.apache.jute.BinaryOutputArchive,或HeapByteBuffer,BinaryOutputArchive)。
查看gc日志,在选举更改前不久,整个GC每4-5分钟运行一次。选举结束后,延长门槛从1提高到15 (最大值),整个GC运行的频率越来越少,最终甚至在某些日子内都不运行。
几天后,突然,神秘地对我来说,一些事情发生了变化,内存急剧下降到200 me,每4-5分钟运行一次完整的GC。
我在这里感到困惑的是,为什么这么多的内存没有GC根,而不被一个完整的GC收集。我甚至尝试过从jcmd触发一个jcmd几次。
我想知道在ZK本土是否有什么东西保存着这个记忆,或者泄露了这个记忆.这就可以解释了。
我正在寻找任何调试建议;我计划升级1.8,也许是ZK 3.5.4,但是在继续之前,我真的很想从根本上解决这个问题。
到目前为止,我已经使用了visualvm、GCviewer和Eclipse。
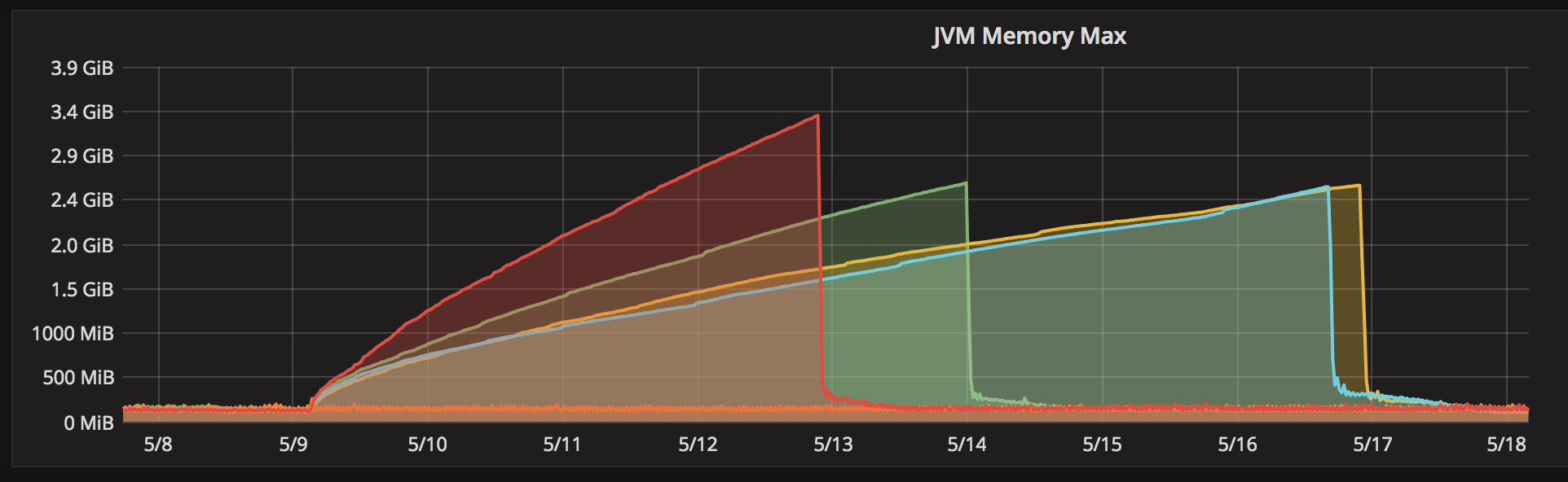
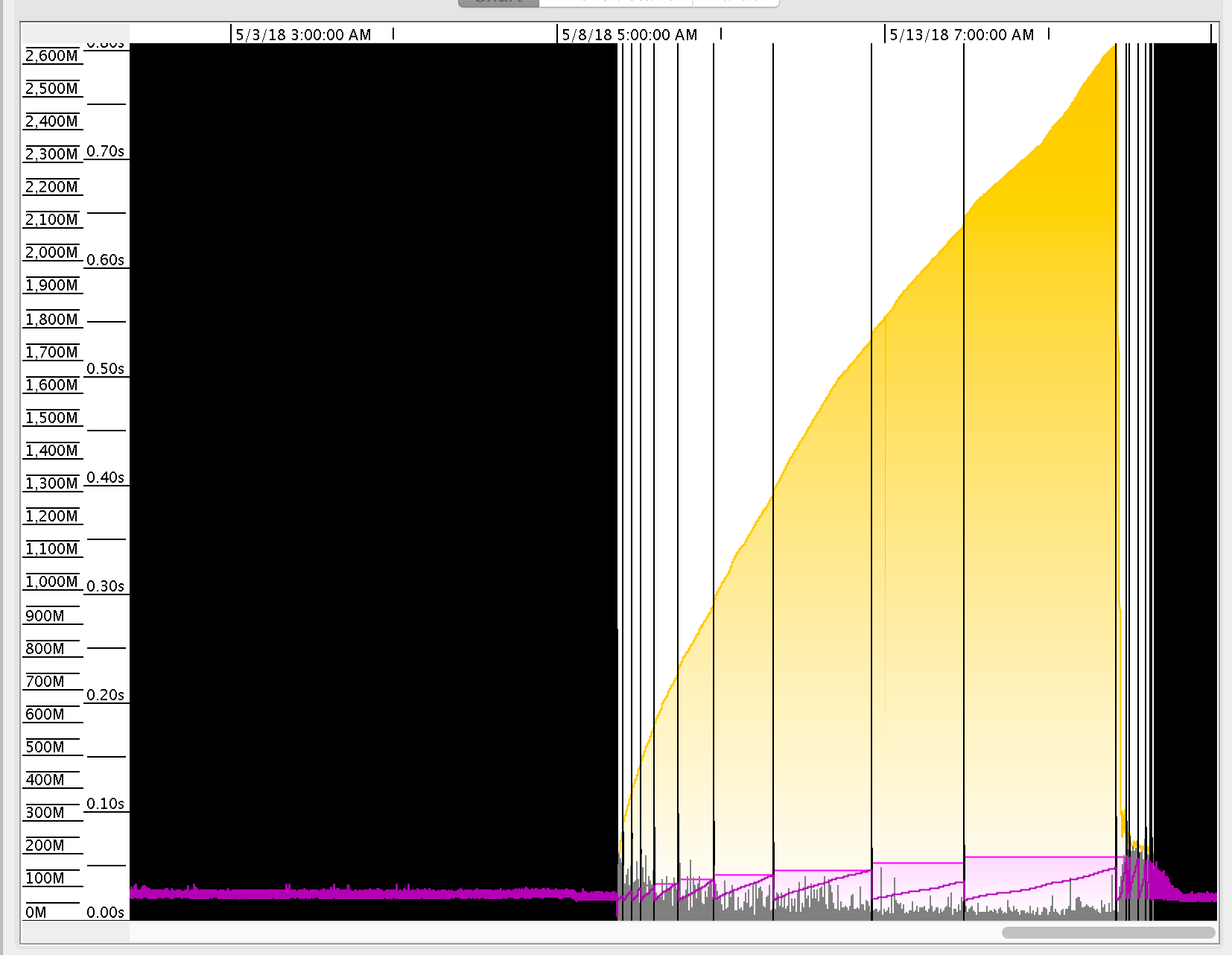
(实心垂直黑线是满GC的。黄色是年轻一代)。
回答 1
Stack Overflow用户
发布于 2018-05-22 21:32:23
我不是ZK的专家。然而,我在Weblogic上调优JVM已经有一段时间了,基于这些信息,我觉得您的配置正在产生堆的扩展和收缩(-Xmx10G -XX:+UseParallelGC)。因此,也许您应该尝试使用-Xms10G和-Xmx10G来避免这种调整。重要的是,每次JVM被调整大小时,都会执行一个完整的GC,因此避免这个过程是最大限度地减少完整垃圾回收数量的一个好方法。
请看这个
“当Hotspot JVM启动时,堆、年轻代和perm生成空间分别分配给由-Xms、-XX:NewSize和-XX:PermSize参数确定的初始大小,并根据需要增量到最大保留大小,即-Xmx、- XX:MaxNewSize和-XX:MaxPermSize。如果内存不像最初指定的那样需要,JVM也可能在运行时缩小实际大小。但是,每个调整大小的活动都会触发一个完整的垃圾收集(GC),从而影响性能。作为最佳实践,我们建议您使初始大小和最大尺寸相同“
来源:http://www.oracle.com/us/products/applications/aia-11g-performance-tuning-1915233.pdf
如果您能够提供您的gc.log,那么彻底分析这个案例将是非常有用的。
向你问好,RCC
https://stackoverflow.com/questions/50437481
复制相似问题
腾讯云开发者
