
YOLO对象检测:该算法如何预测大于网格单元格的边界框?
我正在努力更好地理解YOLO2 &3算法是如何工作的。该算法处理一系列的卷积,直到到达13x13网格为止。然后,它能够对每个网格单元内的对象以及这些对象的边界框进行分类。
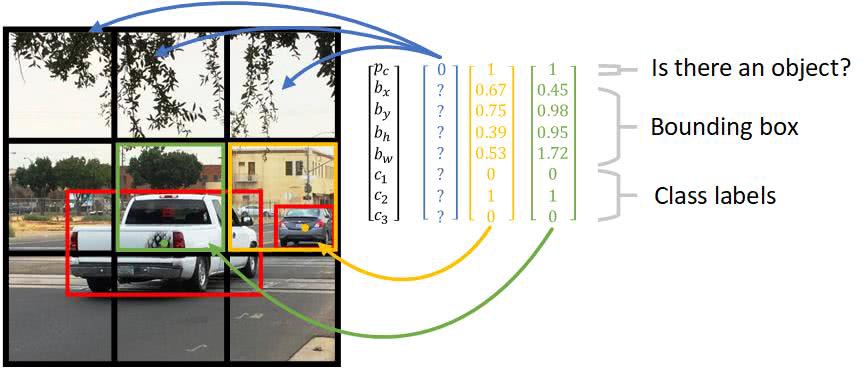
如果您查看这张图片,您将看到红色的边框比任何单个网格单元格都要大。此外,包围框的中心是对象的中心。
我的问题是,当网络激活是基于单个网格单元时,预测的边界框如何超过网格单元的大小。我的意思是,网格细胞以外的所有东西都应该不为神经元所知,这些神经元可以预测在该细胞中检测到的物体的边界框。
更确切地说,这里是我的问题:
1.该算法如何预测大于网格单元格的边框?
2.算法如何知道对象的中心位于哪个单元格中?
Stack Overflow用户
发布于 2019-10-24 15:30:23
好吧,这不是我第一次看到这个问题,对于我在yoloquest中遇到的所有yoloquest体系结构来说,都有同样的问题,网络图在第一层或者图像被输入的那一刻没有暗示某种分类和本地化。它通过一系列卷积层和过滤器(没有忘记池,只是觉得它们是网络中最懒的元素,而且我讨厌游泳池,包括其中的单词)。
- 这意味着在网络流的基本级别上,可以看到或表示不同的信息,从像素到轮廓、形状、特征等,然后才能正确地对对象进行分类或定位,就像在任何正常的CNN中一样。 由于表示边界框预测和分类的张量位于网络的末尾(我看到反向传播的回归)。我认为更恰当的说法是,该网络:
1. divides the image into cells(actually the author of the network did this with the training label datasets)
2. for each cell divided, tries to predict bounding boxes with confidence scores(I believe the convolution and filters right after the cell divisions are responsible for being able to correctly have the network predict bounding boxes larger than each cell because they feed on more than one cell at a time if you look at the complete YOLO architecture, there's no incomplete one). 因此,最后,我的看法是,网络预测一个单元的更大的包围盒,而不是每个单元都这样做--网络可以被看作是一个正常的CNN,它有each classification + number of bounding boxes per cell的输出,其唯一目的是应用卷积和特征映射来用forward pass检测、分类和定位对象。
forward pass暗示分裂中的相邻细胞不会向后/递归地查询其他细胞,通过下一个特征映射和卷积来预测更大的边界框,从而连接到以前细胞分裂的接受区域。此外,方框的中心化是一个函数的训练数据,如果它被更改为最左,它将不会是中心化(原谅语法)。
https://stackoverflow.com/questions/50575301
复制相似问题
腾讯云开发者
