
跨两个具有不同源DB的不同服务器的增量负载
我需要将我们的数据负载从满载改为增量,随着这个变化,我们将重建整个ETL过程。
下面是数据源基础结构现在的样子:
我们有两个生产服务器(针对两个不同的产品),比如P1和P2。在P1上,我们的数据源是两个数据库:位于链接服务器S1上的DB1和DB2。在P2上,链接服务器S1上只有一个数据库DB3。在未来,将为P2添加另一个数据库P2和产品P3。服务器S1上有表示所有数据的SQL视图。
我们的ETL:
用于P1和P2的两个不同的SSIS项目,实际上仅在连接字符串中不同。DB1和DB2由联合所有 SSIS组件直接合并在数据流任务中。当前,SSIS包正在执行存储在任务中的SQL查询,P1中的ETL更改将导致对P2的ETL进行相同的更改。数据每天在P1上加载两次,在P2上每5分钟加载一次,在两个数据仓库中,数据加载都会被截断并加载到暂存表中。
目标:
我们的目标是创建一个具有参数化的通用ETL进程,允许我们在服务器P2上执行P2时使用DB1+DB2,在服务器P1上执行它时使用DB1+DB2,并有可能将其扩展到P3+DB4和DB3。我们还希望将SQL代码从包中移到存储过程中,这样从开发人员的角度来看维护就更容易了。
我们还需要使ETL在P1上更频繁地出现,但同时不允许在链接服务器上在短时间内多次查询整个数据集,这将是P2上的一个问题,因为数据集随着时间的推移而增大。
我们想要避免的事情:动态SQL。
在SSIS中创建增量数据负载和这种参数化的最佳实践是什么?我们经常与负责服务器S1的开发人员保持联系,如果我们需要任何类型的视图,他将能够交付它。
回答 1
Stack Overflow用户
发布于 2018-06-06 15:32:35
我所采取的一般模式是这样的。
我的控制流将识别与我们的项目相关的服务器上的数据库(Connection = Source)
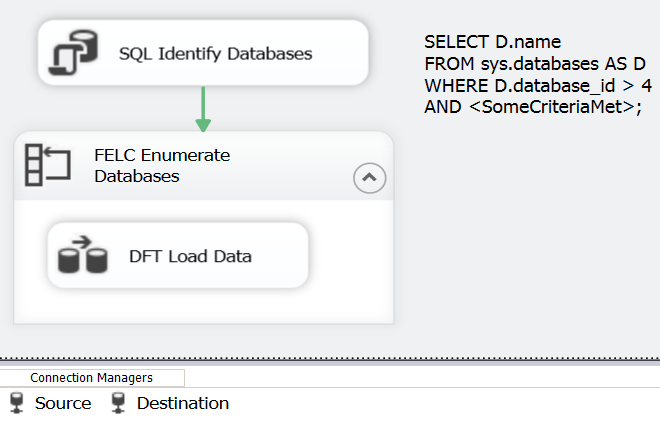
这里我展示了一个针对sys.databases的查询,因为也许您可以应用诸如和D.Name IN ('DB1', 'DB2', 'DB3');这样的条件
在S1上,该查询将返回2个值,在S2上只返回1个。
我们将使用该数据库列表作为ForEach循环枚举器的源,以“分解”结果。对于我们在原始查询(DB1,DB2)中标识的每个值,我们将更新的InitialCatalog属性。在下面的参考答案中,我设置了ConnectionString属性,但是您只想修改InitialCatalog。所以每一个循环,指向的数据库都会改变。
然后,将ForEach枚举器内的数据流简化为只处理当前数据库,而不必担心此服务器是否有3个源数据库或1。
注意事项
源查询和数据类型必须在所有关联数据库之间兼容。数据流的结构是在设计时设置的,在运行时不能更改.
如果这些实体在数据库中是一致的,而且只是调用了不同的列,那么在每个数据库中创建一个视图,以确保实体名称是一致的,这样就可以避免动态SQL。
您将需要在包开始时提供源连接字符串的初始值。这可以通过调用时的SET属性来实现。
参考答案
一些相关的SSIS回答,探索这些概念
https://stackoverflow.com/questions/50696046
复制相似问题
腾讯云开发者
