
matplotlib -使用adjustText对文本进行调整
matplotlib -使用adjustText对文本进行调整
提问于 2018-06-06 06:10:37
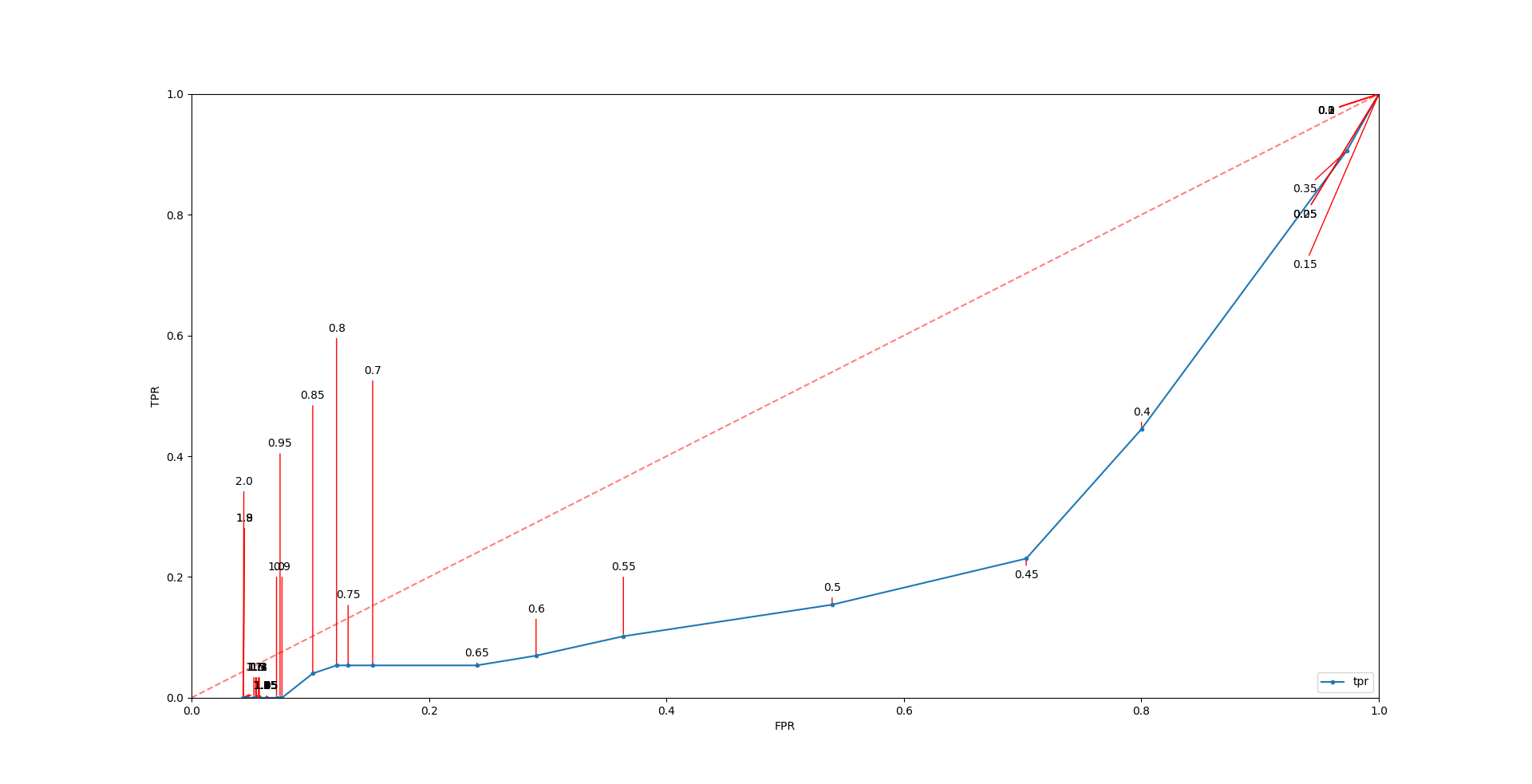
这是我使用pyplot生成的一个图,并且(试图)使用adjustText库来调整文本,我在这里也找到了这个库。
正如您所看到的,在0 < x < 0.1的部分,它变得相当拥挤。我在想,在0.8 < y < 1.0中仍然有足够的空间,这样它们都可以很好地匹配和标记这些点。
我的尝试是:
plt.plot(df.fpr,df.tpr,marker='.',ls='-')
texts = [plt.text(df.fpr[i],df.tpr[i], str(df.thr1[i])) for i in df.index]
adjust_text(texts,
expand_text=(2,2),
expand_points=(2,2),
expand_objects=(2,2),
force_objects = (2,20),
force_points = (0.1,0.25),
lim=150000,
arrowprops=dict(arrowstyle='-',color='red'),
autoalign='y',
only_move={'points':'y','text':'y'}
)其中,我的df是一只熊猫数据,可以找到这里
根据我在文档中的理解,我试图改变包围盒和y-力,使它们变大,以为它会把标签推得更高,但情况似乎并非如此。
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-11-09 16:57:34
我是“adjustText”的作者,很抱歉我注意到了这个问题。你有这个问题,因为你有很多重叠的文本与完全相同的y坐标。通过在标签上添加一个小的随机移动(您确实需要增加文本的作用力,否则在一维上它工作得非常慢),这很容易解决,如下所示:
np.random.seed(0)
f, ax = plt.subplots(figsize=(12, 6))
plt.plot(df.fpr,df.tpr,marker='.',ls='-')
texts = [plt.text(df.fpr[i], df.tpr[i]+np.random.random()/100, str(df.thr1[i])) for i in df.index]
plt.margins(y=0.125)
adjust_text(texts,
force_text=(2, 2),
arrowprops=dict(arrowstyle='-',color='red'),
autoalign='y',
only_move={'points':'y','text':'y'},
)还请注意,我增加了沿y轴的边距,这对拐角有很大帮助。结果并不完美,将算法限制在一个轴上,使生活变得更加困难。但已经没问题了。
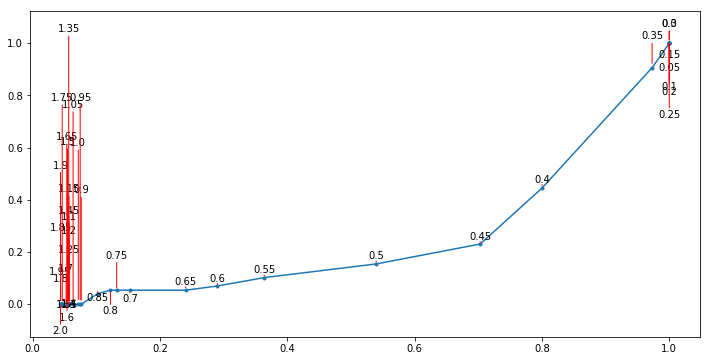
值得一提的是,这个数字的大小很重要,我不知道你的数字是什么。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/50713258
复制相关文章
相似问题
腾讯云开发者
