
用Python平滑的方式绘制时间序列的导数
我有一个像这样的长熊猫时间序列:
2017-11-27 16:19:00 120.0
2017-11-30 02:40:35 373.4
2017-11-30 02:40:42 624.5
2017-12-01 14:15:31 871.8
2017-12-01 14:15:33 1120.0
2017-12-07 21:07:04 1372.2
2017-12-08 06:11:50 1660.0
2017-12-08 06:11:53 1946.7
2017-12-08 06:11:57 2235.3
2017-12-08 06:12:00 2521.3
....
dtype: float64我想把它和它的导数一起画出来。根据定义,我以这种方式计算导数:
numer=myTimeSeries.diff()
denominat=myTimeSeries.index.to_series().diff().dt.total_seconds()/3600
derivative=numer/denominat由于δ时间的一些值(即以面额表示)非常接近(有时等于),所以我在导数中得到了一些inf值。实际上,我得到了这个:
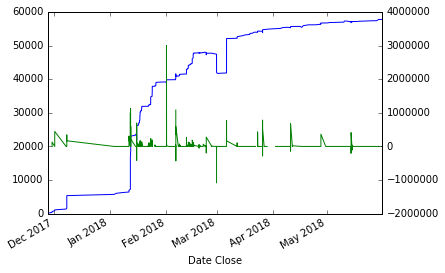
时间序列蓝色(左标度),导数绿色(右标度)
现在,我想平滑导数,使它更加可读性。我尝试过不同的手术,比如:
- 计算较高期间的差额:
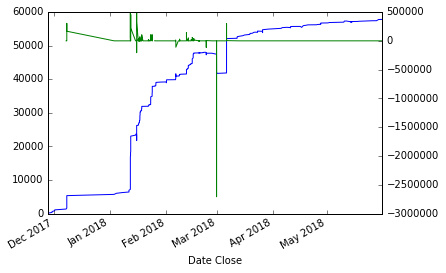
为数字和分母设置periods=5
- 使用移动平均值和:
smotDeriv=derivative.rolling(window=10,min_periods=3,center=True,win_type='boxcar').mean()获取:
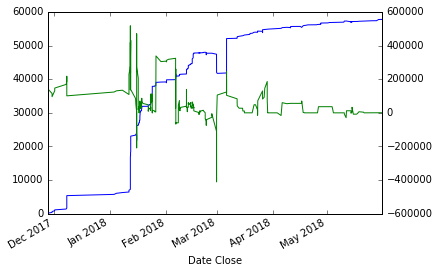
我还使用了不同的窗口类型,没有进行任何有用的更改。
- 我也想剪下这些值,但我不知道用哪个有效值作为最小值和最大值。我尝试了25%和75%的分位数,但没有任何优势。
- 我还绑定了使用pykalman的Kalman滤波器:
derivative.fillna(0,inplace=True) kf = KalmanFilter(initial_state_mean=0) state_means,_ = kf.filter(derivative.values) state_means = state_means.flatten() indexDate=derivative.index derivativeKalman=pd.Series(state_means,index=indexDate)
为了得到这个:
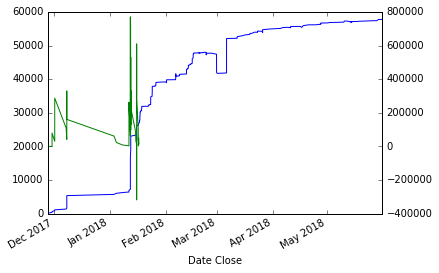
实际上,我找不到任何有用的改进。如果可能的话,你能建议我提高图表上的导数图的可读性吗?很明显,我会剪掉一些导数的峰值,得到一个光滑的曲线,它近似于真值。我尝试过关于窗口类型、句点等的不同组合。没有任何结果。关于卡尔曼滤波器,我不是专家,比如说新手,所以我在这之后使用了默认值。我还找到了filterpy库,它实现了Kalman滤波器,但我没有找到如何在不设置启动参数的情况下使用。
回答 2
Stack Overflow用户
发布于 2018-06-14 23:54:57
如果你的目标是删除衍生产品系列中的“异常值”峰值,我会先尝试“滚动中值”,而不是“滚动均值”,因为中位数在一般情况下对离群点比较不敏感。
例如:
smotDeriv = derivative.rolling(window=10, min_periods=3, center=True).median()然后,如果您想进一步解决它,可能的选择之一是应用rolling_mean()。
注意到:因为我手头没有你的数据,所以我不确定window和min_periods的最优值。这取决于你想要把它解决多远。而且,在我看来,平滑导数变得更像平滑原来的时间序列,所以如果有一种已知的方法来平滑你原来的时间序列,那可能会更直接。
希望这能有所帮助。
Stack Overflow用户
发布于 2018-06-15 00:21:42
我们知道,函数的导数定义如下:
f'(x) = lim_(h -> 0) (f(x + h) - f(x ))/ 2h
让我们假设函数的导数定义在每个地方。当h很小的时候,你会得到一个更好的导数的近似,当h很大的时候,你会得到一个很差的导数的近似。
在数据集的情况下应用此方法存在问题。有时h会变得非常小,本质上给出了极高的梯度值。有时h太大,梯度估计很差。为了克服这个问题,让我们定义两个时间阈值t1和t2。如果逐次时差是t1和t2之间的时差,那么我们就用这个点来用f'(x)的上述公式确定梯度。如果它超过了这个临界点,我们就忽略这一点。
我们如何计算其余点的梯度?
我们可以根据我们在前一步中找到的点来拟合多项式。
https://stackoverflow.com/questions/50766061
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号