
泰国字符在unicode字符串中的问题
我有一串泰文字数很少的字。此字符串使用unicode字符。但是我看不到IDE中的泰语字符,或者即使我在文本文件中写入字符串也是如此。如果我想正确地看到泰语字符,我必须编写以下代码
var text = "M_M-150 150CC. เดี่ยว (2 For 18 Save 2)";
var ascii = Encoding.Default.GetBytes(text);
text = Encoding.UTF8.GetString(ascii);在应用上述逻辑之后,我可以正确地看到带有泰国字符的字符串。这是输出
// notice the thai character เดี่ยว in the string M_M-150 150CC. เดี่ยว (2 For 18 Save 2)
我不知道为什么我需要应用上面的逻辑来查看泰国字符,即使字符串是Unicode?在这种情况下,Encoding.Default到底在做什么?
回答 1
Stack Overflow用户
发布于 2018-06-20 16:04:24
来自MSDN
以下是Encoding.Default性质的含义:
不同的计算机可以使用不同的编码作为默认值,默认编码甚至可以在一台计算机上更改。因此,从一台计算机流到另一台计算机,甚至在同一台计算机上不同时间检索的数据可能会被错误地翻译。此外,默认属性返回的编码使用最佳匹配回退将不受支持的字符映射到代码页支持的字符。出于这两个原因,通常不建议使用默认编码。为了确保正确解码编码的字节,您应该使用带有前导的Unicode编码,例如UTF8Encoding或UnicodeEncoding。另一种选择是使用更高级别的协议,以确保使用相同的格式进行编码和解码。
字符串由Encoding.Default传入,但随后使用UTF8解码,因此瓶颈不是Encoding.Default。它是Encoding.UTF8,它接受字节并正确地将其转换为字符串。
即使你想把它打印在控制台上。看看这两种情况:
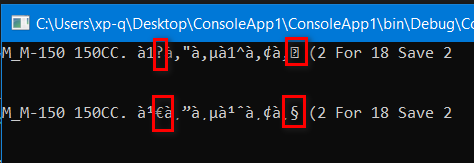
第二行使用utf8配置打印,您可以通过添加以下行来配置控制台以支持utf8:
Console.OutputEncoding = Encoding.UTF8;即使使用您的代码:文件中的结果将如下所示:
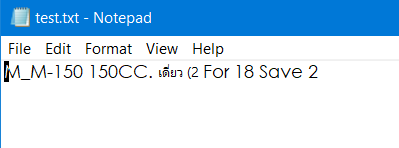
使用Encoding.UTF8将字符串转换为字节时
var text = "M_M-150 150CC. เดี่ยว (2 For 18 Save 2";
var ascii = Encoding.UTF8.GetBytes(text);
text = Encoding.UTF8.GetString(ascii);其结果将是:
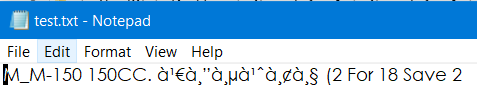
如果您查看支持脚本,您将看到UTF8支持所有Unicode字符
包括泰语。
Note表示Encoding.Default将无法读懂中文或日文,
举个例子:
var text = "漢字";
var ascii = Encoding.Default.GetBytes(text);
text = Encoding.UTF8.GetString(ascii);以下是文本文件的输出:
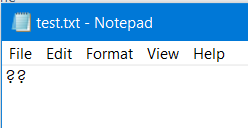
在这里,如果您尝试将它写到文本,它将不会被成功地转换。
所以你必须用UTF8读写它
var text = "漢字";
var ascii = Encoding.UTF8.GetBytes(text);
text = Encoding.UTF8.GetString(ascii);你会得到这个:

因此,正如我所说,整个过程依赖于UTF8,而不是默认编码。
https://stackoverflow.com/questions/50951472
复制相似问题
腾讯云开发者
