
没有显示所有Unicode字符的Eclipse详细格式化程序字符串
我喜欢在调试器中看到剪贴板符号:(U+1F4CB)。
我明白这两个代码点。
韦拉特:
- \ud83d为ߓ
- U8dccb是
我喜欢在Unicode中的调试工具提示中看到它的详细格式。
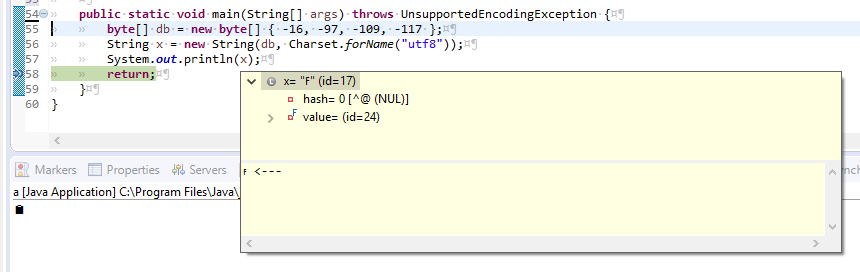
我当前的detail-formatter(Preferences->Java-Debug->Detail格式化程序是:
new String(this.getBytes("utf8"), java.nio.charset.Charset.forName("utf8")).concat(" <---")(上面的代码只不过是在细节视图中添加一个<---而已)
问题1:
我需要什么样的格式化程序才能在黄色工具提示中正确地显示字符?
来源
import java.nio.charset.Charset;
public class Test {
public static void main(String[] args) {
byte[] db = new byte[] { -16, -97, -109, -117 };
String x = new String(db, Charset.forName("utf8"));
System.out.println(x);
return;
}
}回答 2
Stack Overflow用户
发布于 2018-07-02 15:22:53
“”字符是在Unicode字符集中定义的,因为String实例是Unicode字符的序列,因此它们可能包含该字符。但是它位于基本的多语言平面之外,所以软件处理必须更加小心。最值得注意的是,它不能试图将其处理为单独的char值,这是UTF-16单元,需要处理像一对代理字符这样的字符。
详细格式化程序指定为
new String(this.getBytes("utf8"), java.nio.charset.Charset.forName("utf8")) …这里没有帮助,因为this.getBytes("utf8")将Unicode String实例转换为UTF-8编码中的byte[]数组,然后传递给new String(…, Charset.forName("utf8"))构造函数,将字节数组转换回相同的String实例。如果Eclipse的调试器未能呈现原始字符串,那么在该冗余操作之后,它不会突然用相同的字符串正确地执行此操作。
通常,如果Eclipse的调试器无法正确地呈现包含基本多语言平面之外的字符的字符串,那么您在细节格式化程序中就无法修复这个问题,因为您将在那里进行的所有处理,最终都将在String中结束,也许在应用了详细信息表单之后。因此,最终的结果只能是两个选择中的一个,一个删除了问题字符的String,另一个是String调试器无法正确呈现的String。
换句话说,这是一个只能在Eclipse端修复的bug。
Stack Overflow用户
发布于 2018-07-02 07:14:28
您的代码和剪贴板表情在IntelliJ 2018.1中工作得很好。调试器的变量视图和控制台输出都正常工作。
这不太可能是代码的问题。也许是您在Eclipse中使用的字体无法打印出UTF表情符号?我可以想象Eclipse在显示工具提示时理解代码点的概念。
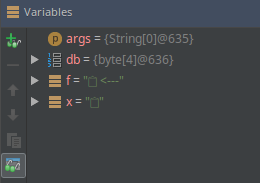
我在IntelliJ中执行的代码:
byte[] db = new byte[] { -16, -97, -109, -117 };
String x = new String(db, Charset.forName("utf8"));
System.out.println(x);
String f = new String(x.getBytes("utf8"), Charset.forName("utf8")).concat(" <---");
System.out.println(f);并在调试器中观察到:
https://stackoverflow.com/questions/50999828
复制相似问题
腾讯云开发者
