
基于文件中的变量合并文件的不同部分
基于文件中的变量合并文件的不同部分
提问于 2018-07-02 07:51:19
我有一个看起来像第一张图片的数据文件,我正在用FILE TYPE MIXED把它读到SPSS,这样它看起来就像第二张图片。如何根据ID变量合并这些案例,以便合并具有相同ID变量的案例?变量Age是重复的,所以选择哪个变量并不重要,但是如果可以选择第一个值,那就更好了。
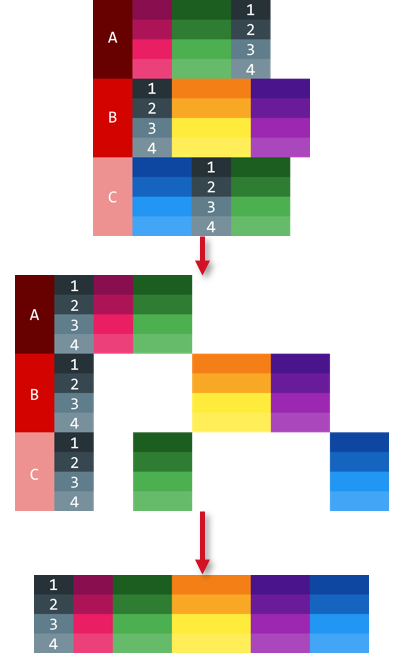
下面是我用来读取数据的代码示例:
FILE TYPE MIXED RECORD=RecordID 1
/ WILD =WARN.
RECORD TYPE 1.
DATA LIST
/ ID 8-9 JobType 3-4 Age 5-7.
RECORD TYPE 2.
DATA LIST
/ ID 3-4 Sex 11 Salary 5-8.
RECORD TYPE 3.
DATA LIST
/ ID 6-7 Age 8-10 Hiring 3-5.
END FILE TYPE.
BEGIN DATA
1 1 39 1
1 3 27 2
1 2 27 3
1 3 25 4
2 1 9000 0
2 2 7500 0
2 3 4750 1
2 4 7250 1
3 76 1 39
3 98 2 27
3 8 3 27
3 44 4 25
END DATA.
LIST.回答 1
Stack Overflow用户
回答已采纳
发布于 2018-07-02 11:00:57
这应该是可行的:
sort cases by ID RecordID.
casestovars id=ID/index=RecordID.如果年龄相同,它们就会缩成一列。如果它们不是,您将得到三个age列,并且您可以选择您喜欢的一个列。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/51131385
复制相关文章
相似问题
腾讯云开发者
