
用neo4j计算数据库中的自引文数
用neo4j计算数据库中的自引文数
提问于 2018-07-13 15:24:55
我已经将DBLP数据库与来自Crossref的参考出版物导入到neo4j中。
目标是为数据库中的每个作者计算一个自引用商。我想计算这个商数的方法如下:
- 查找引用同一作者编写的另一份出版物的作者
- 对于这些出版物中的每一种,计算由同一作者编写的参考出版物。
- 将自我引用的数量除以所有引用的数量
- 将此数字设置为出版物的参数
scq(自引用商) scq的所有值之和,除以作者所写的出版物总数- 将此值设置为作者的属性
scq
作为一个例子,我为作者Danielle S. Bassett提供了以下子图:
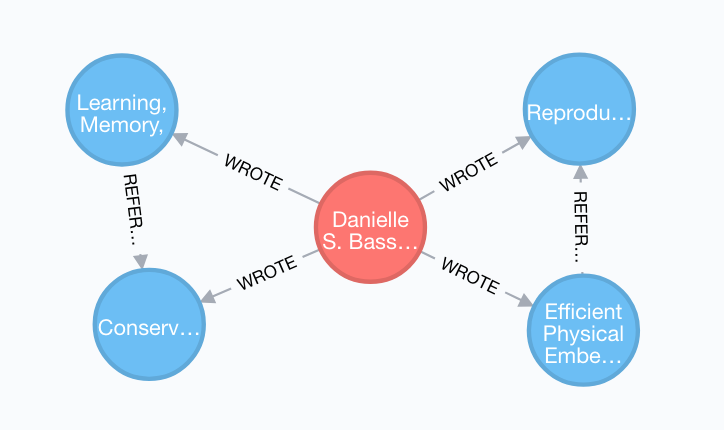
从图中你可以看到,她有两个出版物,其中包含自我引用。丹妮尔写的出版物1,2,3,4出版物1出版物2出版物3出版物4
我的尝试是使用以下密码查询:
match (a:Author{name:"Danielle S. Bassett"})-[:WROTE]->(p1:Publication)-[r:REFERENCES]->(p2:Publication)<-[:WROTE]-(a)
with count(p2) as ssc_per_publ,
count(p1) as main_publ_count,
collect(p2) as self_citations,
collect(p1) as main_publ,
collect(r) as refs,
a as author
return author, main_publ, ssc_per_publ, self_citations, main_publ_count, refs此查询作为表的结果如下所示:

从表中可以看出,main_publ_count是正确计算的,因为她编写了两个包含自引用的出版物,但是ssc_per_publ (每个出版物的自引用计数)是错误的,因为它计算了所有的自引用。但我需要每一份出版物的自我引用数。
计算商不是问题,但从neo4j中获得正确的值是问题所在。
我希望我已经表达得足够清楚,让你理解这个问题。也许你们中的某个人知道一个正确的方法。谢谢!
回答 1
Stack Overflow用户
发布于 2018-07-13 20:58:48
您的WITH子句使用author作为唯一的聚集函数“分组键”,因为它是该子句中唯一不使用聚合函数的术语。因此,该子句中的所有聚合函数都是在这一项上进行聚合的。
要获得每个出版物的“自引用计数”(由该作者提供),您必须执行如下操作(为了简单起见,此查询忽略了所有其他计数和集合)。author和publ一起构成了这个查询中的“分组键”。
MATCH (author:Author{name:"Danielle S. Bassett"})-[:WROTE]->
(publ:Publication)-[r:REFERENCES]->(p2:Publication)<-[:WROTE]-(a)
RETURN author, publ, COUNT(p2) as self_citation_count;[旁白:您最初的查询也有其他问题。例如,您应该使用COUNT(DISTINCT p1) as main_publ_count,以便对同一个p1实例的多个自引用不会夸大“主”发布的计数。]
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/51328394
复制相关文章
相似问题
腾讯云开发者
