
星火/分布式算法的时间复杂度
星火/分布式算法的时间复杂度
提问于 2018-07-20 14:16:43
如果我们的时间复杂度低于
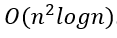
对于某些顺序算法,如何表示在Spark (分布式版本)中实现的相同算法的时间复杂度。假设集群中有一个主节点和三个工作节点?
同样,我们如何表达星火算法的O(n^2)时间复杂度?
此外,如何在具有复制因子3的HDFS中表示空间复杂性?
提前谢谢!
回答 1
Stack Overflow用户
发布于 2022-02-26 17:37:47
忽略编排和沟通时间(这通常不是这样的,例如。在对整个数据进行排序的情况下,操作不能只是在不同的分区上“拆分”)。
让我们做另一个方便的假设:数据在这3个分区之间被完美地划分:每个节点都包含n/3数据。
这就是说,我认为我们可以把O(n^2)算法看作是三个O((n/3) ^ 2)部分计算的总和(因此是一个最终的O((n/3) ^ 2))。对于任何其他复杂性( O(n^2 log n)将是O((n/3)^2 log(n/3)) ),情况也是如此。
对于hadoop中的复制因子,考虑到上述假设,由于这些操作将在副本之间并行执行(!=来自分区),其复杂性将与单个“副本”的执行相同。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/51444566
复制相关文章
相似问题
腾讯云开发者
