
Tesseract不识别png文件中的captcha,该文件包含英文字母的数字和字母。
Tesseract不识别png文件中的captcha,该文件包含英文字母的数字和字母。
提问于 2018-08-01 08:30:18
我需要从url中提取captcha,然后用Tesseract来识别它。我的代码是:
#!/usr/bin/perl -X
###
$user = 'user'; #Enter your username here
$pass = 'pass'; #Enter your password here
###
#Server settings
$home = "http://perltest.adavice.com";
$url = "$home/c/test.cgi?u=$user&p=$pass";
#Get HTML code!
$html = `GET "$url"`
###Add code here!
#Grab img from HTML code
if ($html =~ m%img[^>]*src="(/[^"]*)"%s)
{
$img = $1;
}
###
die "<img> not found\n" if (!$img);
#Download image to server (save as: ocr_me.img)
print "GET '$home$img' > ocr_me.img\n";
system "GET '$home$img' > ocr_me.img";
###Add code here!
#Run OCR (using shell command tesseract) on img and save text as ocr_result.txt
system("tesseract ocr_me.img ocr_result");
print "GET '$txt' > ocr_result.txt\n";
system "GET '$txt' > ocr_result.txt";
###
die "ocr_result.txt not found\n" if (!-e "ocr_result.txt");
# check OCR results:
$txt = 'cat ocr_result.txt';
$txt =~ s/[^A-Za-z0-9\-_\.]+//sg;
$img =~ s/^.*\///;
print `echo -n "file=$img&text=$txt" | POST "$url"`;图像解析正确。此图像包含captcha,如下所示:
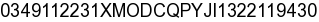
我的产出是:
GET 'http://perltest.adavice.com/captcha/1533110309.png' > ocr_me.img
Tesseract Open Source OCR Engine v3.02.02 with Leptonica
GET '' > ocr_result.txt
Captcha text not specified正如您所看到的,脚本正确地解析图像。但是Tesseract没有在PNG文件中看到任何东西。我试图使用shell命令tesseract指定额外的参数,如-psm和-l,但这也没有给出任何结果。
更新:在阅读了“戴夫·克罗斯”之后,我已经听过他的建议了。
在输出中我得到:
http://perltest.adavice.com/captcha/1533141024.png
ocr_me.img
Tesseract Open Source OCR Engine v3.02.02 with Leptonica
[]
200Captcha text not specified
Original image file not specified
Captcha text not specified为什么我需要来自图像.PNG的文本?也许这些额外的信息能帮到你。看看这个:
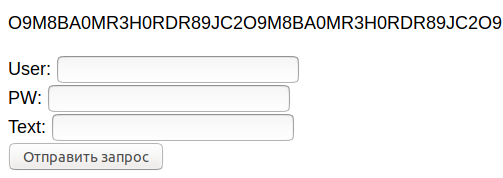
这就是$url在浏览器中的样子。我的目标是使用perl在wim中为这个页面创建查询。为此,我需要在我的$user、$pass和$txt上面填写表格(使用Tesseract图像识别)。并将其与POST 'url‘(代码中的最后一个字符串)一起发送。
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-08-01 10:04:44
这里发生了一些奇怪的事情。他们中的任何一个都可能引起你的问题。
- 让
-X出现在你的线上是个糟糕的主意。它显式地关闭警告。我建议您删除它,将use warnings添加到您的代码中,并修复所有暴露出来的问题(我也建议添加use strict,但您需要声明所有变量)。 - 我建议使用LWP::简单来代替
GET。 - 请不要使用regexes解析HTML。使用真正的HTML解析器。Web::查询是我目前最喜欢的。
- 然后再次运行
GET,使用一个名为$txt的变量,该变量没有值。那是行不通的! $txt = 'cat ocr_result.txt'不做你认为它做的事情。你要的是后排,而不是单引号。
更新:显然,我没有访问您的用户名或密码的权限,所以我无法重构您的所有代码。但是,对于访问示例中的图像并从中提取文本来说,这似乎很好。
#!/usr/bin/perl
use strict;
use warnings;
use feature 'say';
use LWP::Simple;
my $img_url = 'http://perltest.adavice.com/captcha/1533110309.png';
my $img_file = 'ocr_me.img';
getstore($img_url, $img_file);
my $txt = `tesseract $img_file stdout`;
say $txt;以下是您的实际错误:
system("tesseract ocr_me.img ocr_result");
print "GET '$txt' > ocr_result.txt\n";
system "GET '$txt' > ocr_result.txt";您要求tesseract将其输出写入ocr_result.txt,但两行之后,您将该文件覆盖到对GET的一个失败调用的输出。我不知道您认为这会做什么,但是它会破坏tesseract已经存储在该文件中的输出。
更新:
下面是我当前版本的代码:
#!/usr/bin/perl
use strict;
use warnings;
use feature 'say';
use LWP::Simple qw[$ua get getstore];
use File::Basename;
###
my $user = 'xxxx'; #Enter your username here
my $pass = 'xxxx'; #Enter your password here
###
#Server settings
my $home = "http://perltest.adavice.com";
my $url = "$home/c/test.cgi?u=$user&p=$pass";
#Get HTML code!
my $html = get($url);
my $img;
###Add code here!
#Grab img from HTML code
if ($html =~ m%img[^>]*src="(/[^"]*)"%s)
{
$img = $1;
}
my $img_url = $home . $img;
my $img_file = 'ocr_me.img';
getstore($img_url, $img_file);
say $img_url;
say $img_file;
# Looks like tesseract adds two newlines to its output -
# so chomp() it twice!
chomp(my $txt = `tesseract ocr_me.img stdout`);
chomp($txt);
say "[$txt]";
$txt =~ s/\W+//g;
my $resp = $ua->post($url, {
u => $user,
p => $pass,
file => basename($img),
text => $txt,
});
print $resp->code;
print $resp->content;我改变了几件事。
- 将
$img_url从$url . $img更正为$home . $img(这是阻止它获取正确图像的原因)。 - 切换到使用LWP::简单贯穿整个过程(只是更容易)。
chomp编辑(两次!)从tesseract中移除换行符的输出。- Used::Basename以获得要在最终
POST中传递的正确文件名。 - 在使用
$txt之前,从POST中删除任何非单词字符。
但还是不太好用。它似乎在等待服务器的响应。但恐怕我没时间帮你了。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/51628713
复制相关文章
相似问题
腾讯云开发者
